How to Find and Cluster Long-Tail Keywords to Capture Low-Competition Traffic

People often say that long-tail keywords are easier to rank for and convert better, but most marketers completely misunderstand what makes a search phrase 'long-tail'. We consistently see teams waste their budgets chasing massive head terms because they misunderstand this mechanism. While long-tail keywords attract fewer monthly searches individually, they make up the vast majority of total search traffic and offer much lower competition.
Take a local specialty coffee roaster trying to build an online audience and increase e-commerce sales. If they write a comprehensive guide targeting a high-volume head term like 'coffee beans', they usually end up stalled on page eight of Google results. Targeting highly competitive head terms without established domain authority wastes time and resources.
We've watched countless teams chase impossible head terms and ignore the massive volume of less competitive searches sitting right below the surface. This article provides a complete framework for identifying, clustering, and ranking for low-competition search queries.
Quick Takeaways: Mastering Long-Tail Keywords
- Long-tail keywords are highly specific search queries that fall into the low-volume end of the search demand curve, defined by their clear user intent rather than just their physical word count.
- Targeting hyper-specific phrases instead of broad head terms can drastically increase your revenue, as these late-stage buying queries often convert at significantly higher rates with a fraction of the competition.
- Spread your risk and steadily build deep topical authority by creating a pillar-and-cluster content architecture that compounds the traffic of dozens of targeted, low-volume wins.
- Organize your newly discovered queries by analyzing actual search engine results overlap instead of superficial text matching to prevent keyword cannibalization and structure chaotic data into logical themes.
- Avoid the trap of obsessing over individual daily rankings for low-volume phrases by measuring the cumulative impression and click growth of your entire content cluster over a 90-day period.
- Discover immediate traffic opportunities by auditing your existing analytics data for highly specific queries already ranking on page two or three, then systematically building new dedicated pages to capture that demand.
Definition and mechanics of long-tail search
The 80/20 rule of search demand distribution
The 'long tail' refers to the visual shape of a search demand curve, not the physical length of the words typed into a search bar. If you plot all search demand on a graph, a tiny percentage of keywords get massive search volume. In the U.S. database alone, there are just under 18,000 keywords with search volumes of more than 100,000 searches per month. That sounds like a lot until you look at the whole picture. When you zoom out to a database of 27.2 billion keywords, the vast majority sit in the long, trailing tail of that graph. A full 92% of all keywords get 10 or fewer searches per month.
Length versus intent: a critical distinction
We often see teams confuse low search volume with high word count. A five-word phrase can be a high-volume head term, while a two-word phrase can be a low-volume long-tail query. What actually defines the tail is specificity and search intent. Someone typing "buy Ethiopian Yirgacheffe" knows exactly what they want. They have bypassed the research phase and moved straight into a transaction. The length of the phrase matters less than the precision of the request. Think of the search bar as a diagnostic tool. A broad query requires the search engine to guess what the user wants, returning a mix of definitions, videos, and shopping pages. A specific query forces the search engine to return a highly targeted answer.
Why the long tail dominates total traffic
The long tail is where the internet actually lives. People make over 70% of search queries using long tail keywords. That distribution happens because humans search conversationally and specifically. They ask weird questions, describe niche problems, and use infinite variations to express the same basic need. When you shift your focus from chasing the head to capturing the tail, you stop competing with billion-dollar brands and start answering the exact questions your specific buyers are asking. Most beginners look at a keyword with 20 searches a month and assume it's a waste of time. They fail to realize that those 20 searches represent actual human beings with highly specific problems looking for immediate solutions.
Comparing Head Terms and Long-Tail Keywords
| Attribute | Head Terms | Long-Tail Keywords |
|---|---|---|
| Search volume | High (often 100k+ searches) | Low (often 10 or fewer) |
| Competition level | Extremely high | Significantly lower |
| User intent | Broad research | Late-stage buying |
| Average conversion rate | Standard | Averages around 36% |
| Cost per click | Premium pricing | Up to 50% lower |
| Share of total searches | Under 30% | Over 70% |
The business value of long-tail keywords
Capturing late-stage buying intent
The most compelling reason to target the long tail is the direct impact on revenue. These highly specific, late-stage buying queries convert significantly better than generic head terms. Data suggests they convert at a rate roughly 2.5 times higher, with average conversion rates reportedly sitting around 36% for these precise phrases. For our local specialty coffee roaster, ranking for "coffee beans" brings in window shoppers who might just want to know how coffee is made. Ranking for "organic decaf espresso beans for cold brew" brings in a customer with a credit card in hand. Intent beats volume every time, and the long tail is built on clear intent.
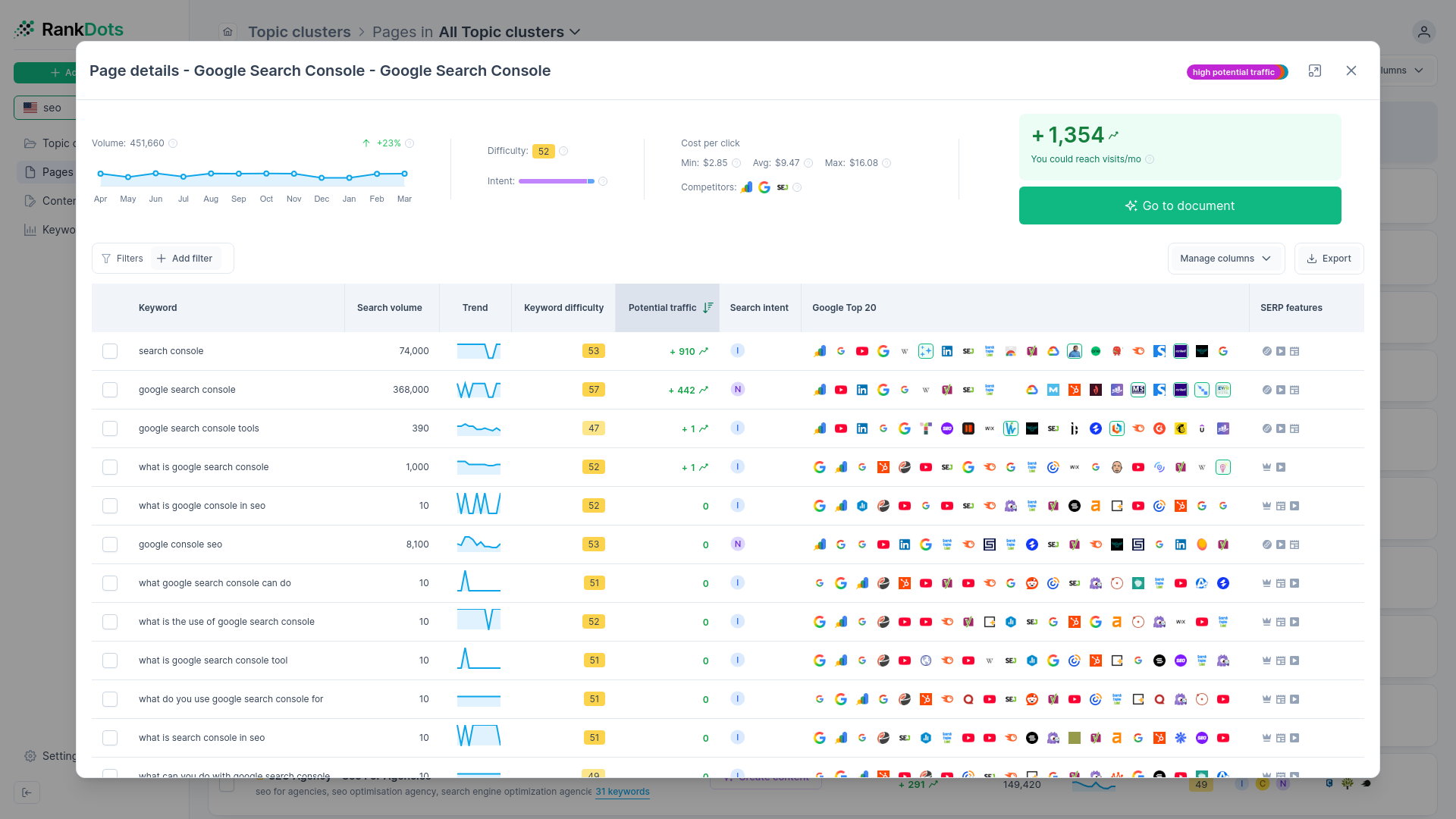
Reduced competition and cost efficiency
The lack of search volume scares away major competitors. Large media publishers and enterprise brands rarely dedicate resources to a topic that only generates 30 searches a month. This lack of competition creates a distinct cost-efficiency advantage in organic search results. You don't need thousands of backlinks to rank for a hyper-specific query. It translates directly to paid channels as well, where targeting these terms can lower your average cost per click by up to 50%. You simply don't have to bid against enterprise budgets for hyper-specific queries.
The compounding effect of low-volume wins
A single query with 20 searches a month won't transform a business. Targeting hundreds of interconnected low-volume queries will. We've seen teams build entire businesses on the compounding traffic of these small wins. Instead of betting a whole quarter's budget on one flagship piece of content that might never rank, you spread the risk across dozens of highly targeted pages. This approach builds topical authority steadily. It creates a reliable stream of organic traffic that holds up exceptionally well against algorithm updates. When one broad page drops in rankings, it hurts. When you have two hundred highly specific pages, a single drop barely registers.
Keyword research methods and tools
The limits of manual discovery
Most marketers start their research by manually typing queries into Google. They scrape autocomplete suggestions and mine the 'People Also Ask' boxes for niche topics. This manual method works fine for finding a few initial ideas. With platforms like AnswerThePublic, you can map these autocomplete search queries into visual question wheels to see raw user intent from multiple platforms. But manual scraping is tedious and won't scale for a six-month content calendar. You might spend three hours mapping out one topic, only to realize you have no data on whether anyone actually searches for those phrases. That manual process simply doesn't scale.
The spreadsheet trap in traditional platforms
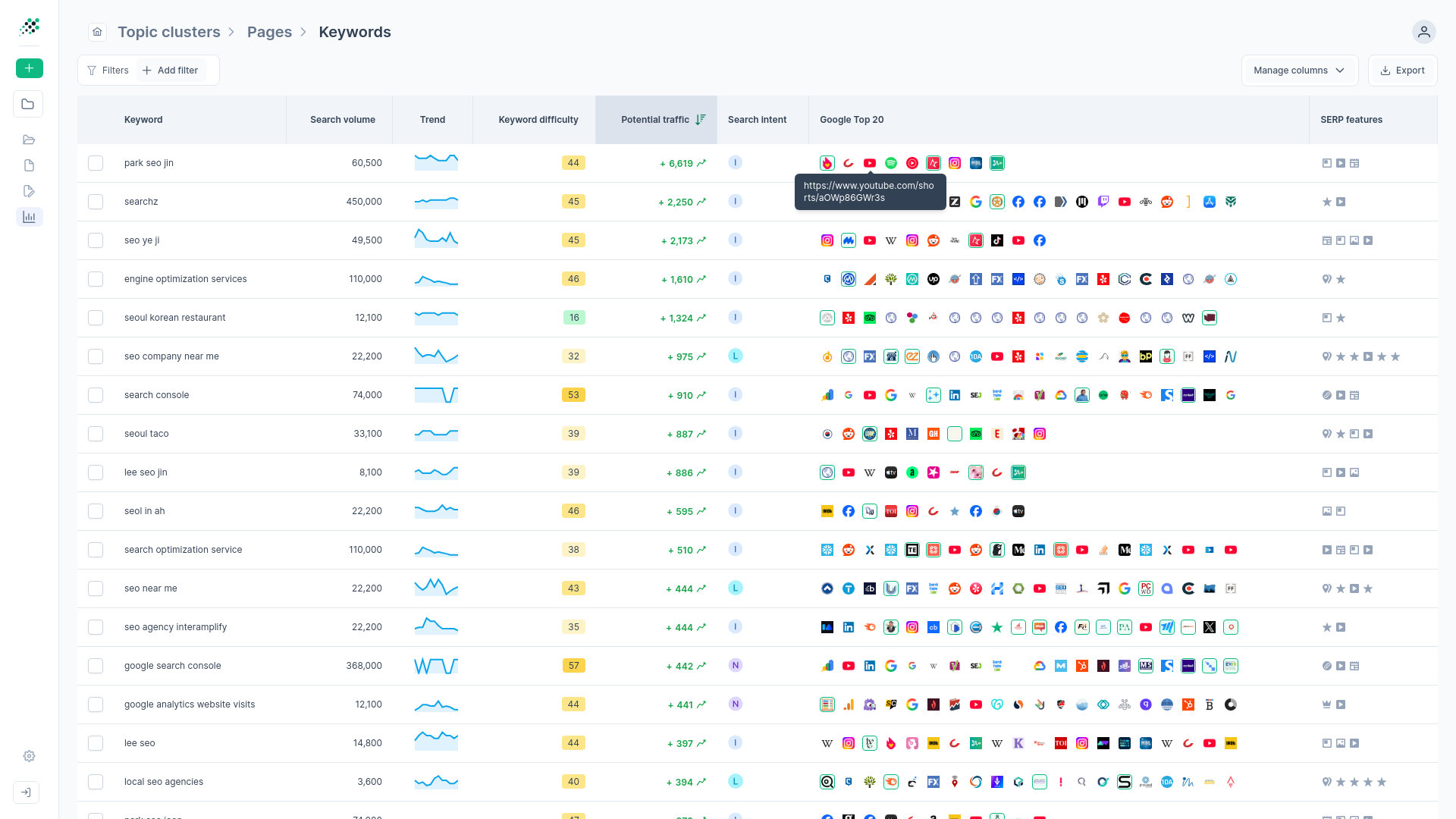
But what happens when you need search volume data for all those ideas? The next logical step is upgrading to a traditional SEO software platform. Tools like Semrush and Ahrefs excel at reverse-engineering competitor link profiles and tracking organic visibility. Ubersuggest offers an accessible entry point for basic keyword overviews. But when you export thousands of keywords from these platforms, you end up staring at a giant, disorganized spreadsheet. We watch teams suffer from analysis paralysis because they can't filter out the junk data or determine which long, multi-word phrases actually carry commercial intent. It's just endless, contextless rows of data. You end up sorting by search volume, which pushes you right back into the highly competitive head terms you were trying to avoid in the first place.
Traditional keyword research tools deliver raw metrics, but they leave the hardest part of the job to you. When you have to act as a human algorithm trying to piece the intent puzzle together, scaling your content production becomes nearly impossible.
Automating discovery with AI-powered pipelines
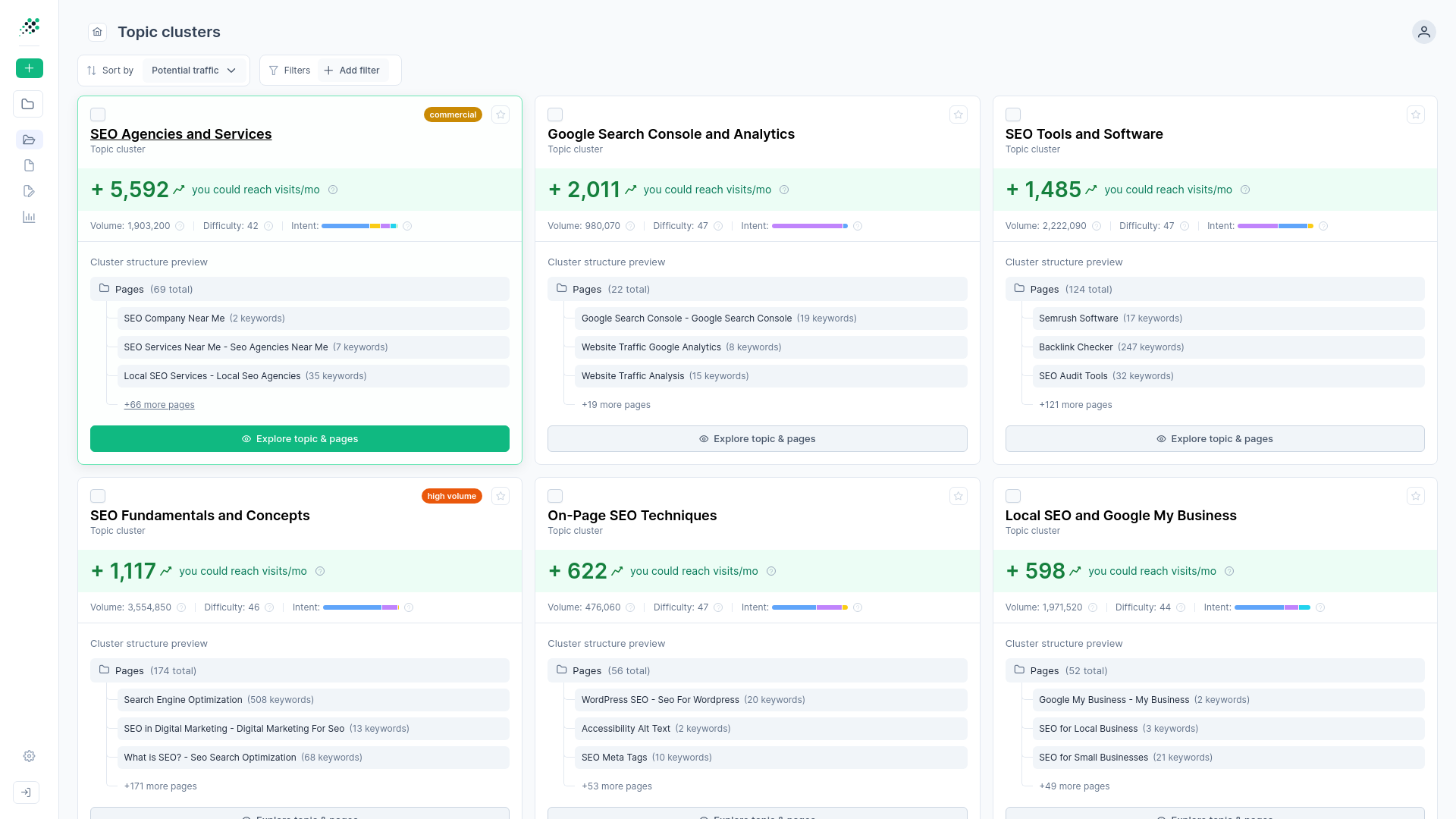
Modern workflows skip the manual spreadsheet sorting entirely. With RankDots AI-Powered Brainstorming, you can analyze a seed input and automatically generate targeted starter keywords. You can kick off discovery by creating commercial variations, informational queries, and problem-solution patterns. You can automatically validate every phrase against linguistic rules, removing the junk but specifically preserving legitimate edge cases that represent highly specific, low-hanging fruit. When you input a broad topic into this pipeline, it instantly generates hundreds of highly specific content angles. If the system collects too many keywords, it smartly trims the least valuable ones. If it needs more data, it automatically triggers related searches to dig deeper. That automated approach replaces manual spreadsheet filtering with a ready-to-use content pipeline.
Content optimization and implementation tactics
Grouping by SERP overlap, not text matching
But how do you structure hundreds of variations without cannibalizing your own pages? Once you have a list of 500 newly discovered long-tail keywords, you have to organize them carefully. A major struggle is determining which specific variations mean the exact same thing to a search engine and should be targeted on a single page versus split into several. You can solve this using RankDots SERP-Based Keyword Clustering. Guessing based on shared words leads to errors — you can use a proprietary machine-learning algorithm to group thousands of keywords based on real Google search engine results page overlap instead. If the exact same pages rank for "best cold brew beans" and "top coffee for cold brewing", they go in the same cluster. This semantic approach structures chaotic data into logical, actionable themes. You know how many pages you need to build.
We lean heavily on semantic clustering because it groups keywords by actual meaning rather than superficial text matching. When the system understands that two completely different phrases carry the exact same intent, you stop building redundant pages that cannibalize your own rankings.
Building a pillar-and-cluster architecture
These clusters map directly into a pillar-and-cluster website architecture. A broad pillar page covers the head term, while dozens of cluster pages target the specific long-tail variations, all linked together. The impact of this structure is substantial. Websites that implement a topic cluster architecture experience an average organic traffic increase of 43% compared to sites using isolated keyword targeting. The architecture signals deep topical authority to search engines.
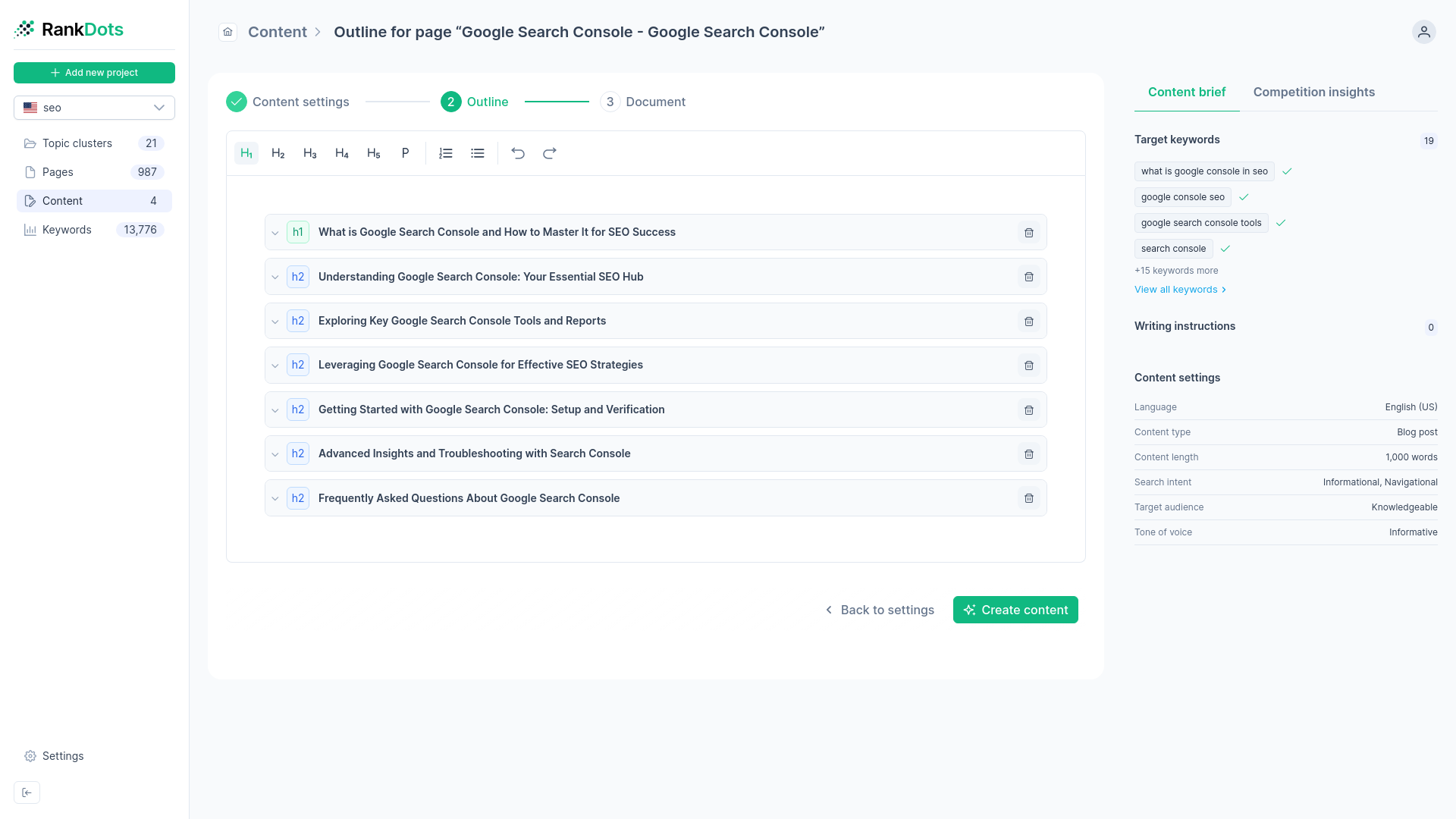
Optimizing the page for semantic variations
The final step is translating a raw list of grouped keywords into a fully structured, SEO-ready article. You don't want to awkwardly stuff every variation into the text. That approach reads terribly and rarely works anymore. Instead, use the cluster to inform your document structure. If your coffee roaster is writing about cold brew beans, the long-tail variations become H2s and H3s answering specific questions about grind size, steep time, and origin profiles. Embedding these variations naturally creates a comprehensive piece of content that satisfies multiple specific intents at once. When the content easily ranks for obscure queries and begins driving highly qualified, late-stage traffic, the entire clustering strategy proves its worth.
Real-world industry examples
Application to a targeted content calendar
When teams try to build a content calendar around head terms, they usually write five generic posts and hit a wall. The long-tail discovery process changes that dynamic entirely. Pick up the thread with our specialty coffee roaster. Instead of slapping "coffee beans" on a generic product category page, they use automated discovery to map out a highly specific commercial cluster. They build a central pillar page for "cold brew coffee beans" and then surround it with six targeted cluster articles. One month's editorial calendar focuses entirely on "best coarse grind beans for cold brew," while the next tackles "how long to steep light roast cold brew." That sequence creates a highly focused publishing schedule that naturally builds deep topical authority.
Transitioning to low-difficulty clusters
This transition from a broad, low-converting head term to a highly specific cluster solves two major problems. First, it bypasses the high domain authority requirements of the generic terms. You're no longer competing with Wikipedia or Amazon. Second, it aligns perfectly with the exact intent of an active buyer. We've seen this structural shift revive flat organic traffic graphs. A real-world e-commerce case study of a CBD supplier demonstrated a 557% increase in organic search traffic over 12 months by shifting their strategy to target low-difficulty long-tail keywords organized into SEO content clusters. While the industries differ, the underlying mechanism is completely universal. Grouping enough specific, low-competition queries together reliably out-performs gambling your budget on a single high-volume head term.
Tracking cumulative organic growth
The biggest mistake you can make with this approach is tracking the wrong metrics. If you monitor a single long-tail keyword that gets 30 searches a month, the daily traffic looks like a flatline. The volume is simply too low for daily rank tracking to provide meaningful feedback. You have to measure the aggregate. Group the URLs of your entire cluster in Google Search Console and filter for that specific directory path. Stop stressing over the individual daily rankings of a single page — look at the cumulative impression growth and total clicks across the entire topic over a 90-day window. This macro view shows you the actual footprint of your cluster. As the interconnected pages start sharing authority, you'll typically see a rising tide effect where the entire group begins to lift together. You have to track the entire cluster's performance over time.
Frequently asked questions
What is the difference between long-tail and short-tail keywords?
How long can long-tail keywords actually be?
Are long-tail keywords still useful for PPC and Google Ads?
How do you track long-tail keyword rankings?
Conclusion and next steps
Stop fighting the search demand curve
The obsession with raw search volume is probably the most expensive mistake in modern organic strategy. The numbers lie. When you chase head terms, you spend months fighting for rankings you might never achieve, only to realize the resulting traffic doesn't convert well anyway. When you accept the reality of the search demand curve, you stop fighting enterprise brands for the top 10% of queries. You deliberately shift your resources into the long tail where the competition thins out and the searchers are ready to purchase.
Prioritize user intent and semantic grouping
We always recommend prioritizing user intent and semantic grouping over raw numbers. A tight cluster of twenty highly specific pages generating 50 visitors apiece is vastly more valuable than a single broad page generating 1,000 visitors who bounce immediately. The goal isn't merely acquiring eyeballs. The goal is capturing specific commercial demand. When you group your keywords by actual search engine results overlap, your content architecture matches how search algorithms understand topics today. It prevents keyword cannibalization and ensures every piece of content you publish serves a distinct, measurable purpose.
Auditing for immediate long-tail gaps
You rarely have to start from scratch. Most established websites are sitting on a goldmine of accidental long-tail rankings right now. To find them, you need to audit your existing content footprint. Open your analytics platform or run a domain analysis in RankDots, enter your top-performing URLs, and look for specific queries where you currently rank on page two or three. These represent your immediate long-tail gaps. You already possess baseline authority for the topic. Identify which existing pages are accidental catch-alls for highly specific queries. Once you extract those queries, run them through a clustering tool to group them logically. Then, systematically build out new, highly targeted pages to capture that traffic properly. Start with the data you already own.
Stop fighting for head terms and capture ready-to-buy traffic.
Stop guessing which long-tail keywords to target. Automate your discovery pipeline to find specific, low-competition phrases that convert. Start mapping your next profitable content calendar right now.