Modern Methods for Keyword Clustering and Topic Modeling Without Python

When you export a massive list of terms from a keyword planner, the immediate bottleneck is grouping them. Most marketers executing enterprise content strategy waste days scrolling through 30,000-row spreadsheets just to sort queries manually. The sheer volume makes it mathematically impossible for most teams to categorize enterprise datasets by hand. We need better methods for keyword clustering and topic modeling without Python to ship architectures that work.
The primary methods for keyword clustering and topic modeling include manual spreadsheet sorting, semantic NLP analysis, and automated SERP-based agglomerative clustering. While manual methods drain days of productivity, modern tools analyze live search engine results to group keywords sharing the exact same search intent. This approach bypasses the complex data science algorithms previously required to prevent cannibalization.
We're sharing a complete strategic framework for understanding modern clustering algorithms, manual sorting limits, and advanced SERP overlap analysis. You'll walk away knowing how to deploy a cannibalization-free, hierarchical site architecture.
Quick Takeaways
- The primary methods for keyword clustering and topic modeling include manual spreadsheet sorting, semantic NLP analysis, and automated SERP-based agglomerative clustering.
- Manual keyword categorization quickly reaches a mathematical breaking point, often resulting in duplicated effort, metric inaccuracies, and massive drains on team productivity.
- Relying strictly on natural language processing and text similarity risks keyword cannibalization because shared linguistics rarely equate to identical search engine intent.
- Analyzing live search engine results page overlaps provides a highly accurate, data-science-grade solution to grouping keywords without requiring complex Python code.
- Accurately classifying search intent into informational, navigational, or transactional categories ensures you allocate resources to the exact page format users actually expect to see.
- Transforming flat data into a logical two-level hierarchy of comprehensive pillar pages and supporting subtopics can drastically increase organic traffic while protecting your site from algorithmic shifts.
Concept definition: Keyword clustering and topic modeling
The fundamental difference between a keyword and a topic dictates how modern search engines rank pages. When someone types an exact string of characters into a search bar, that's a keyword. But the search engine evaluates the underlying concept they actually want—the topic. We noticed this shift years ago when Google's Hummingbird update impacted roughly 90% of all search queries globally. That update changed how search engines process text from simple matching to true semantic understanding.
That specific release forced the industry to stop optimizing for isolated text strings and start optimizing for connected concepts.
Because search engines now evaluate concepts rather than isolated strings, targeting individual keywords with individual pages creates immediate architectural problems. If you create one page for "CRM software" and a separate page for "customer relationship management tools," the search engine has to choose between them. This splits your ranking authority.
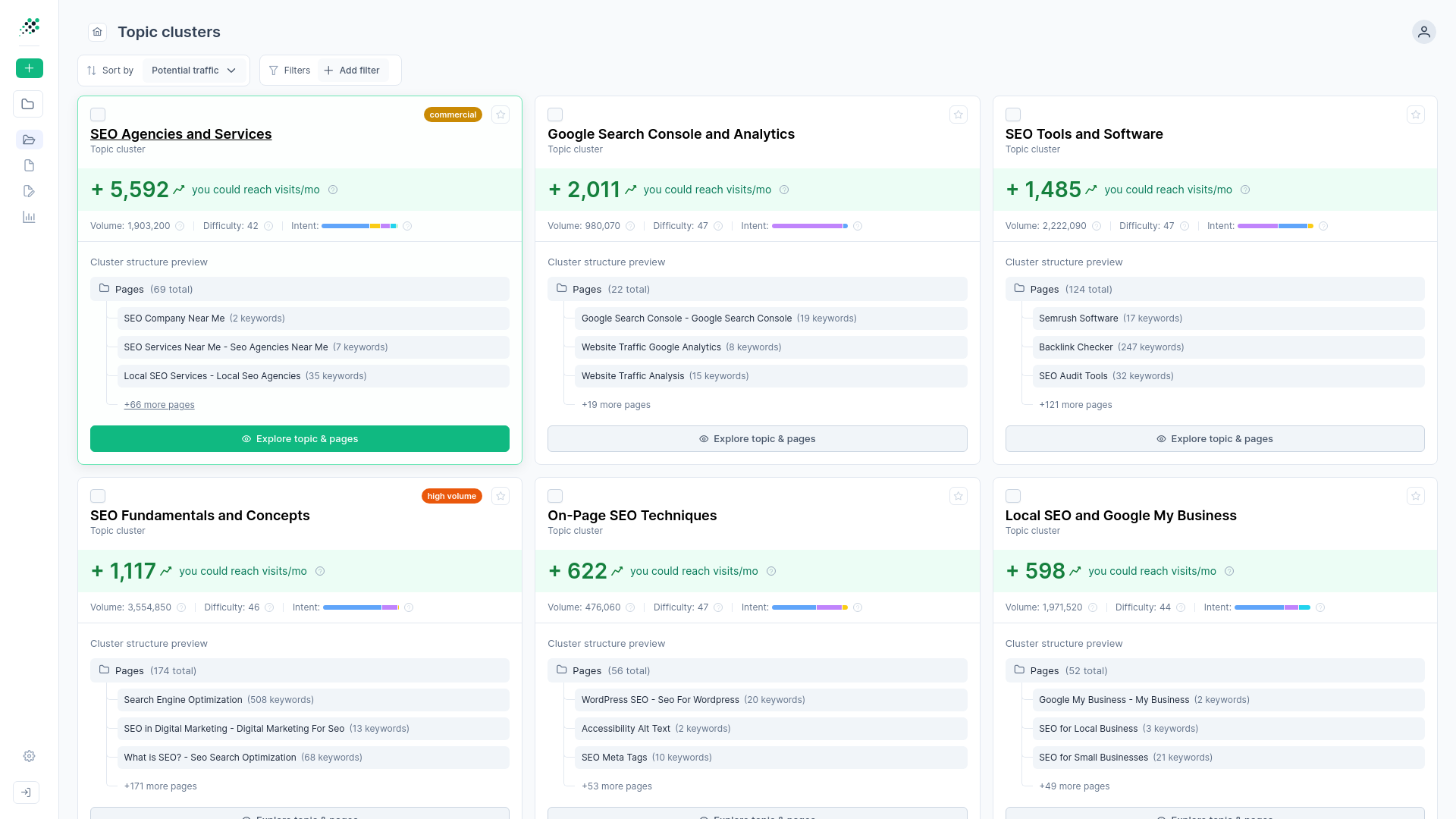
A unified topic cluster ensures your content matches the engine's conceptual understanding. The industry has moved away from keyword-first mapping toward a topic-first hierarchical methodology. You start by defining the core subject area and let the associated search terms flow underneath it. This structural approach protects your site from minor algorithm adjustments because you're answering the user's core intent, not chasing specific phrasing trends.
Automated vs. manual clustering
The reality of spreadsheet sorting
Most content strategists start by sorting keywords by hand. You export a raw list, drop it into Excel, and start applying filters based on gut feeling. The problem becomes immediately apparent when scaling up. In our experience, teams typically spend an average of 10 to 15 hours per week manually researching, categorizing, and managing keywords in spreadsheets. It's a massive resource drain.
Consider a B2B SaaS startup trying to map out a comprehensive resource center without cannibalizing their core transactional product pages. The content lead exports thousands of terms and attempts to sort them logically. The sheer volume of data overwhelms the team's capacity to cross-reference every term against live search results, which causes grouping errors and duplicated content efforts.
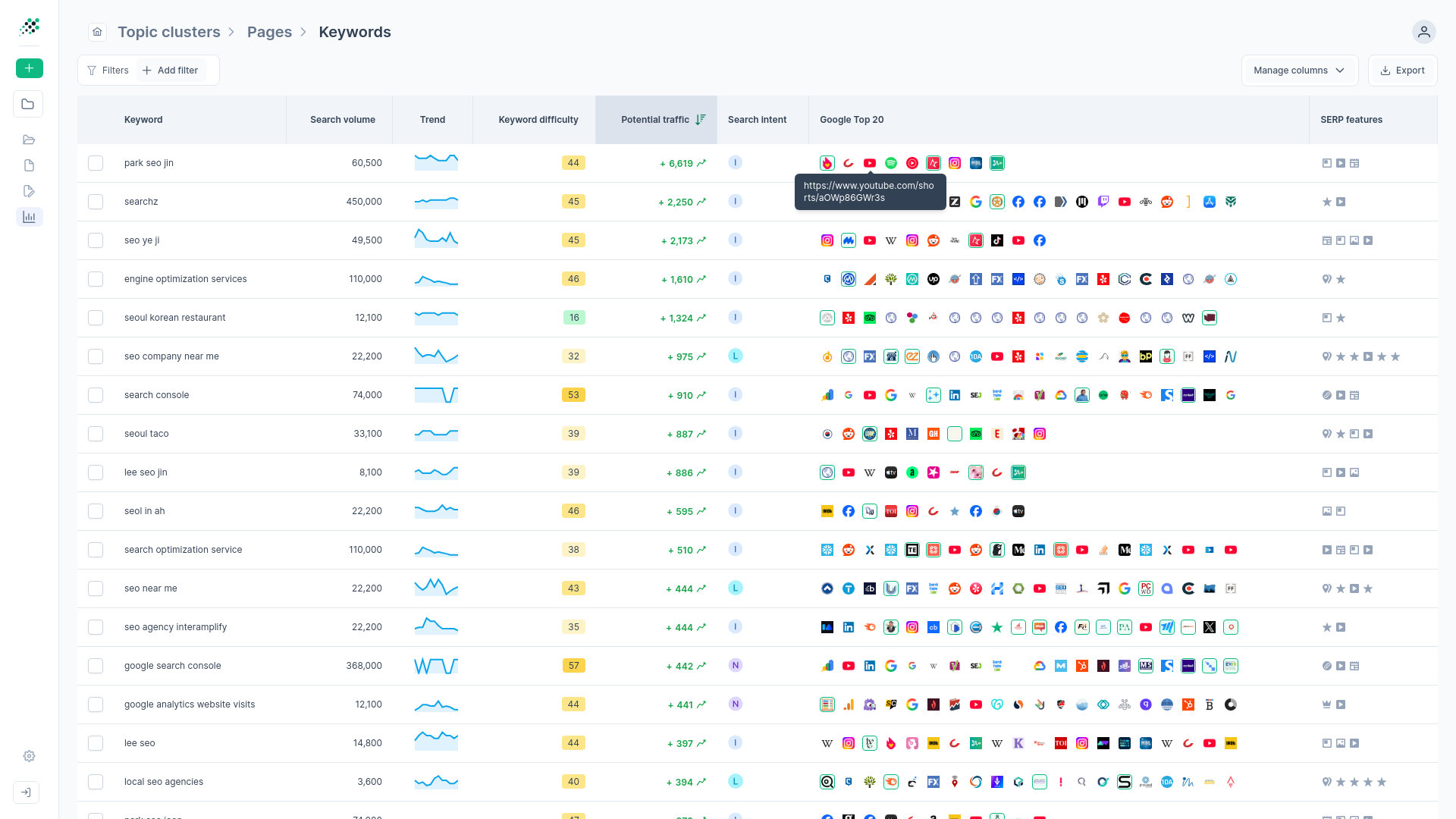
Data accuracy and metric fingerprints
Manual sorting also inherits the raw data inaccuracies of the source tool. Basic keyword planners group similar terms and report the combined search volume for each individual variation. If "running shoes" and "shoes for running" both show 10,000 monthly searches, a manual spreadsheet will incorrectly calculate 20,000 total searches for the group.
To solve this, use a platform like RankDots to apply a search volume correction algorithm. It detects keywords with identical metric fingerprints—meaning they share the exact same search volume, trend pattern, and paid competition level—and distributes the volume among the group members. This volume correction provides realistic traffic estimates that flat spreadsheets can't offer.
The mathematical breaking point
The mathematical threshold where manual cross-referencing becomes impossible hits earlier than most anticipate. To verify the intent of just 500 keywords, you have to check 5,000 individual search results to confirm overlap. Automation replaces this guesswork with objective, scalable processing.
Clustering algorithms
Mathematical classification takes over where manual sorting fails. Foundational machine learning models evaluate datasets quickly. A multinomial Naive Bayes classifier achieves 92.4% overall accuracy for keyword categorization. Support Vector Machines offer slightly better precision, with 93.6% overall accuracy for the same classification tasks. These models represent the gold standard for data science categorization.
The catch is the steep technical barrier to entry. Running these local, script-based data grouping workflows traditionally requires dedicated Python programming expertise. You have to install libraries, clean the raw data, tune the algorithm parameters, and handle the output formatting. For most marketing departments, hiring a data scientist to group keywords is an unreasonable expense.
Even using generalized AI models like ChatGPT presents significant friction. You can prompt an LLM to execute Python code for data processing and generate visual charts, but you'll immediately hit tight context windows and usage limits. You still need advanced prompt engineering skills and perfectly formatted data structures to get a usable output.
Modern SEO platforms package these advanced classification algorithms into accessible, no-code interfaces. You get the mathematical precision of high-end machine learning without needing to write a single line of code or wrestle with environment variables. The technology has shifted from a developer's toolset to a strategist's dashboard.
NLP and semantic similarity methods
How text co-occurrence works
Natural Language Processing attempts to group keywords by analyzing the linguistic similarities between them. The algorithm breaks down phrases, strips away stop words, and looks for text co-occurrence. You can use tools like InfraNodus to generate text co-occurrence network graphs and detect structural gaps in discourse. If two phrases share common root words or established synonyms, the NLP model assumes they belong to the same topic category.
This method shines when mapping out broad themes or discovering new linguistic relationships within a dataset. It groups "affordable software" and "cheap software" because the language model understands the synonym connection.
The risk of linguistic guesswork
The fundamental disconnect happens because linguistic synonym matching doesn't always reflect search engine realities. Two queries can share identical words but demand entirely different user experiences. Someone searching for "CRM implementation checklist" wants a PDF download or a quick guide. Someone searching for "CRM implementation services" wants an agency landing page. An NLP model sees the shared text and groups them. A search engine sees the differing intent and demands separate pages.
Semantic keyword clustering tools average a quality score of just 33-47 out of 100 in practical testing. Text-based NLP clustering alone elevates the risk of keyword cannibalization. You end up combining terms that Google expects to see separated, or separating terms that Google expects to see combined.
SERP-based agglomerative clustering
The mechanics of live search overlap
The most accurate way to understand how search engines view a query is to look at what they actually rank. Agglomerative clustering works bottom-up to group search terms strictly on shared ranking assets. Semantic models analyze the words in the query, but this method analyzes the URLs in the live search results.
When a strategist exports their list and discovers automated clustering based on live search engine results page overlap, the entire workflow changes. They finally have a reliable way to confirm that visually different queries share the exact same search intent. If you search for "cheap auto insurance" and "affordable car coverage", the words share zero overlap. But if six of the top ten URLs are identical for both searches, the engine considers them the exact same topic.
Reverse-engineering search intent
Reverse-engineering ranking choices provides a definitive, data-science-grade solution to the high failure rate of basic text-similarity models. Tools using SERP-based methods average a quality score of 70-89 out of 100—a vast improvement over semantic guesswork.
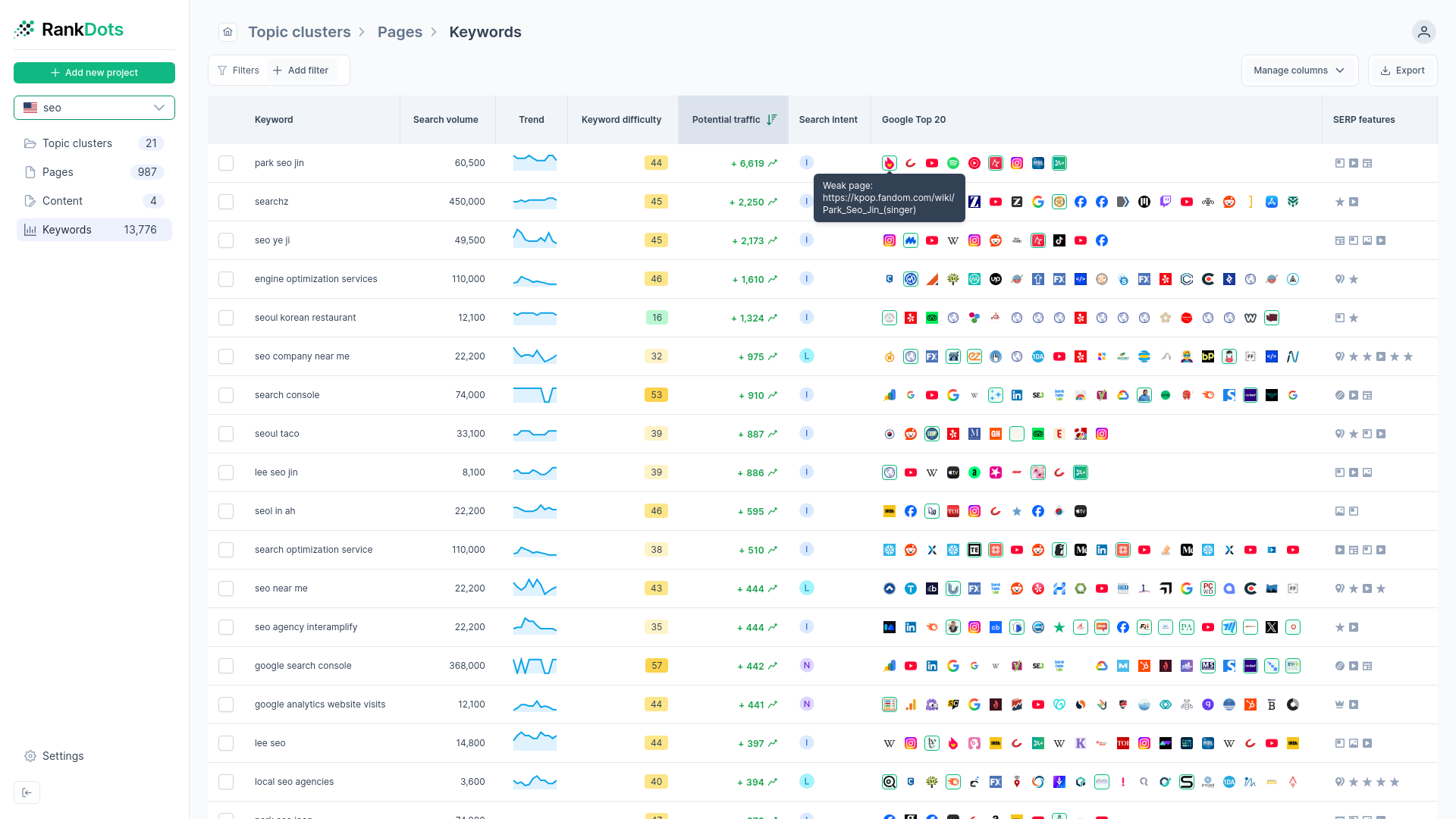
You can use RankDots to deploy SERP-based agglomerative clustering in your workflow. It includes URL intersection validation as a unique quality check. After grouping, the algorithm verifies if the same URLs actually rank for multiple keywords within the cluster. If they don't, the system recognizes the topic is too broad and separates it. Platforms like Ahrefs and Semrush also incorporate varying degrees of automated grouping, but validating exact URL intersections is what prevents accidental cannibalization.
Keyword intent classification
The final filter before content creation begins is categorizing mapped clusters by their dominant intent.
Proper search intent classification ensures your team builds what the user actually wants to see, so you don't allocate resources to the wrong page format. You need to know whether the user wants to learn, navigate, or buy. We've seen that roughly 80% of searches are informational in nature, while navigational and transactional searches each account for approximately 10% of total query volume. If you treat an informational cluster like a transactional one, you guarantee poor performance.
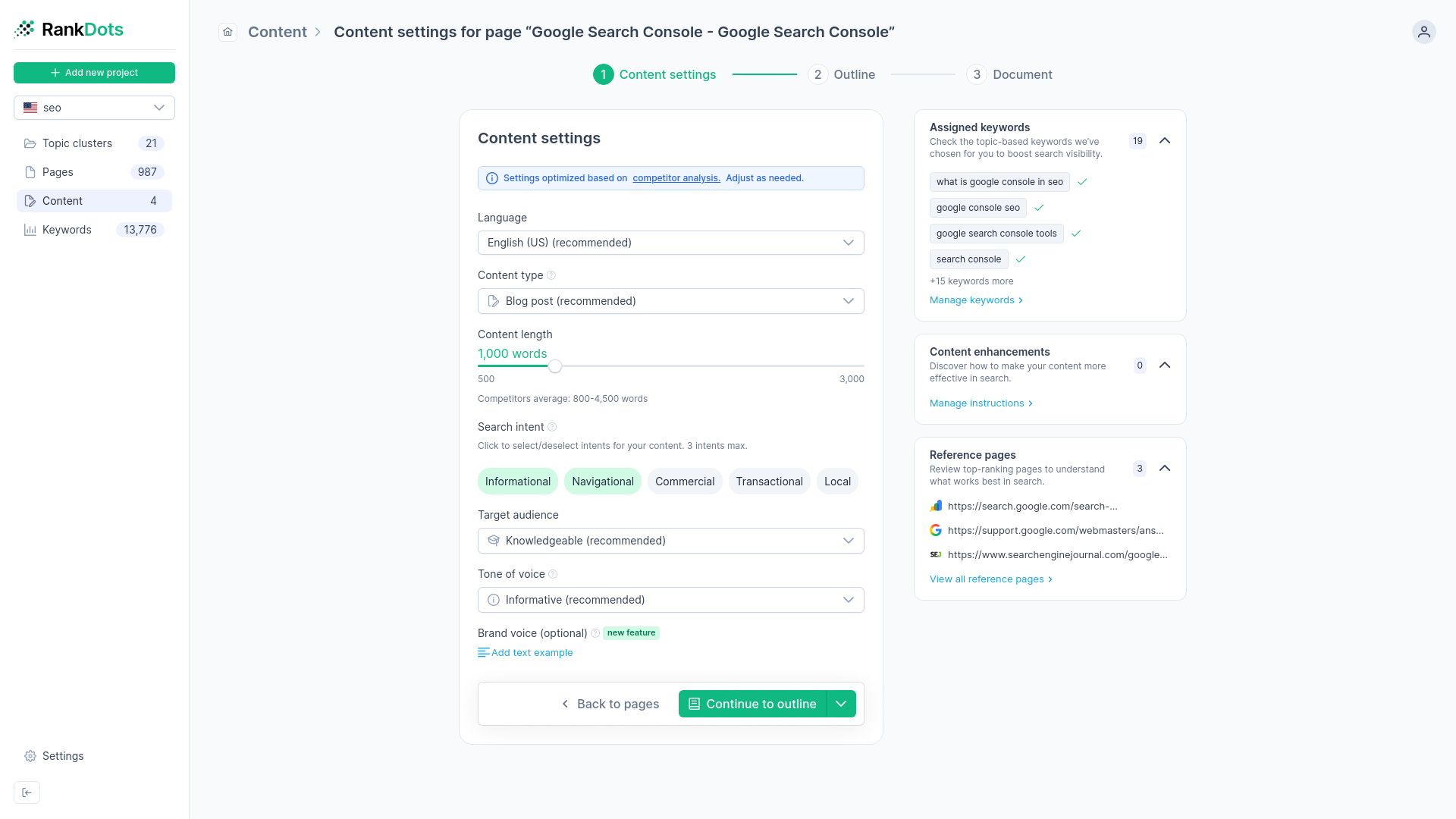
Align your content formats to the classified intent profile. A purely informational cluster demands a long-form guide or a detailed tutorial. A transactional cluster requires a product comparison or a direct sales page. You can use tools like Keyword Insights to assign search intent labels to clusters and generate accurate content briefs. You can also use Clearscope and its SERP-based grading system to ensure the resulting text matches the required depth.
Content and architectural gaps become obvious when you review intent mismatches on your existing pages. If your main product page is trying to rank for a cluster dominated by informational intent, you have an architectural flaw. The solution is rarely to rewrite the product page. You build a new informational pillar and link it back to the product. Proper classification forces you to build what the user wants.
Structural pillar and cluster workflow
Building the two-level hierarchy
The main goal of clustering is to turn flat analytical data into a logical architecture. You need to move from a list of buckets to a structured two-level hierarchy of main parent topics and specific subtopics. The parent topics become your comprehensive pillar pages. The subtopics become the supporting blog posts that link upward.
When a content strategist needs to present a new website architecture to stakeholders, a flat spreadsheet fails to communicate the vision.
A clear pillar-cluster site architecture solves this by showing how individual subtopics roll up to support primary category pages. Websites that implement a structured topic cluster architecture experience an average organic traffic increase of 43% compared to websites using a flat, isolated targeting approach. You can enforce a topic-first architecture using RankDots to organize your data into this exact Topic → Page → Keyword hierarchy. This structure bridges the gap between having a list of phrases and knowing exactly what pages to build.
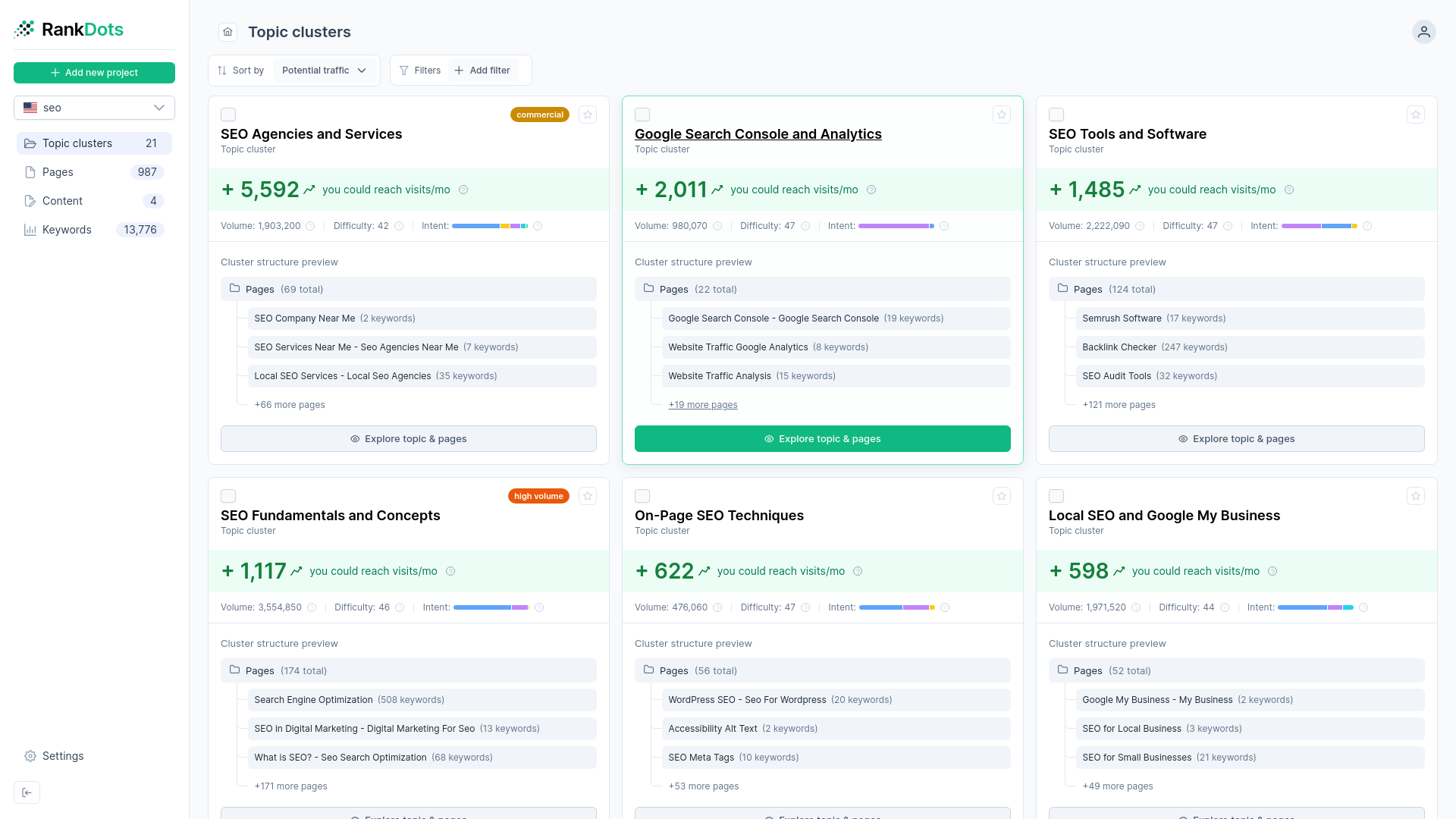
Prioritizing content rollouts
The next hurdle is sequencing the work. When you have a mapped-out topical architecture but a limited quarterly budget, prioritize aggressively. You can't determine ROI by looking at single keywords. Evaluate the aggregate cluster difficulty and the combined monthly traffic potential of the entire topic area.
A prioritized content rollout sequence relies on calculated growth potential. Use RankDots to highlight entire topic clusters with weak competition based on aggregated difficulty scores and search volumes. You tackle the low-competition clusters first to build initial authority. Enterprise platforms like InLinks and WordLift also push toward entity-based, structured deployments, but the core strategy remains the same: target the entire cluster's traffic potential, not isolated search terms.
Frequently Asked Questions
What are the main methods for keyword clustering and topic modeling?
How does clustering differ from classification in keyword research?
How can machine learning speed up keyword research?
What is SERP-based agglomerative clustering?
How do you organize keyword clusters by search intent?
Conclusion
The industry has shifted away from manual spreadsheet sorting toward automated SERP overlap analysis. Basic text similarity and gut feeling are guaranteed paths to keyword cannibalization and wasted content budgets when categorizing enterprise datasets. True topical alignment requires evaluating the live search results to see how algorithms group concepts in real time.
Adopt a topic-first architecture immediately. A strict parent-and-subtopic hierarchy protects your existing rankings against future algorithmic shifts. When you build pages based on validated search intent instead of isolated text strings, you stop fighting the engine and start aligning with it.
Map your entire site architecture without sorting another spreadsheet.
Transition to automated methods for keyword clustering and topic modeling to group terms by live search intent. Our platform categorizes thousands of queries instantly to give you a clear blueprint for your next content rollout. Stop guessing and start capturing highly relevant traffic.