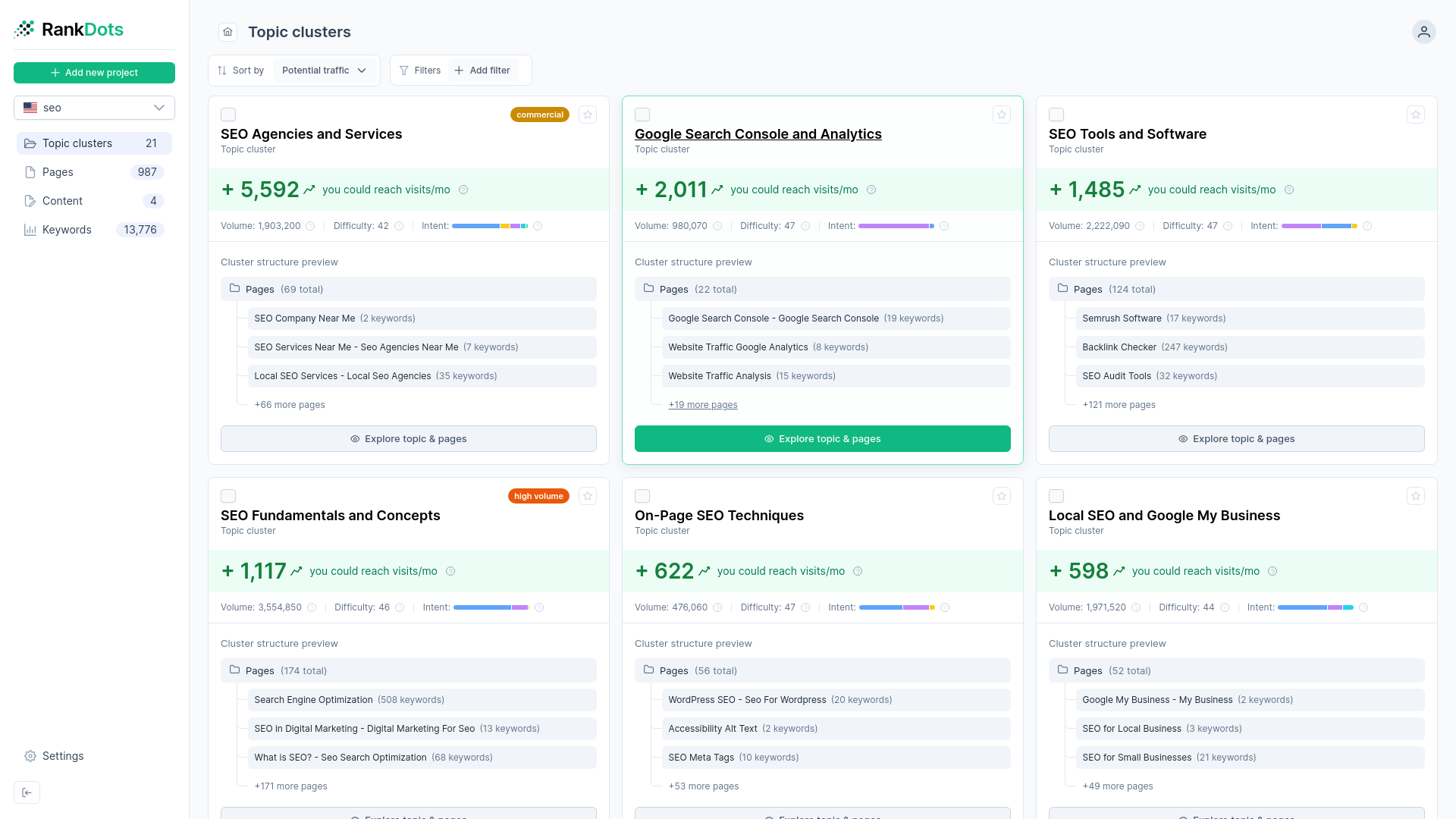
How to Use Keyword Clustering to Build True Topical Authority

Most SEO strategies start similarly: someone has exported thousands of keywords from a research tool, staring at a massive spreadsheet trying to manually group the terms. With keyword clustering, instead of creating individual pages for every keyword variation, you create one comprehensive page that ranks for the entire group.
This structured approach prevents self-competition and builds a clear site architecture that search engines can easily understand.
In this guide, we cover a five-step framework to transition from a chaotic, flat keyword list to a topic-first web hierarchy, grouping your raw keyword data into high-traffic pillar pages and supporting clusters.
Quick Takeaways
- Keyword clustering is the strategy of grouping search terms by underlying meaning and user intent rather than shared vocabulary, allowing a single comprehensive page to rank for an entire group.
- Transitioning from a flat spreadsheet of keywords to a topic-first site architecture requires mapping broad parent clusters to central pillar pages and specific variations to supporting subtopics.
- Evaluating the aggregate search volume of an entire cluster rather than isolated terms drastically shifts content prioritization and helps mitigate accidental keyword cannibalization.
- Relying on live URL intersection—checking if the same pages rank on the first page for multiple queries—is the most reliable, data-driven method to validate shared search intent.
- Bypassing manual spreadsheet sorting in favor of an automated workflow bridges the crucial gap between raw SEO research and the creation of perfectly aligned content briefs.
What is keyword clustering?
For years, organizing keywords meant looking for shared words. If a list contained "time tracking software" and "software for time tracking," they went into the same bucket. If it contained "employee hours app," it went into another. That's superficial text overlap, and it stopped working a long time ago.
True keyword clustering groups terms by meaning and search intent, regardless of whether they share any actual words. The evolution of machine learning and natural language processing has shifted search engine behavior from recognizing simple synonyms to understanding complex semantic clusters, making exact-match keywords less important.
This distinction matters because approximately 15% of all daily searches Google processes are entirely new queries that the search engine has never encountered before. If your site architecture relies on exact-match targeting, it breaks the moment users search for something unexpected.
When we look at how a mid-sized B2B software company structures a blog about workforce management, the legacy approach would mean writing one post for "staff scheduling app" and another for "employee shift planner." A modern, intent-based clustering approach recognizes these terms satisfy the exact same user need and groups them into a single comprehensive topic.
Topic vs keyword clusters
It's easy to confuse a grouped list of search terms with a finished content strategy. They aren't the same thing. Keyword clusters are the raw data input, while topic clusters form the strategic structural output of your website.
Moving from data to architecture
A keyword cluster simply tells you which terms mean the same thing and belong on the same page. If an SEO strategist is tasked with overhauling a blog's architecture, having fifty grouped keyword lists doesn't automatically create a hierarchy. The real challenge is logically connecting those isolated groups into a structure that proves expertise.
That structure is the topic cluster. It transforms flat data into a web architecture by establishing relationships between different pages.
The role of pillar pages
A topic cluster relies on a central hub, typically called a pillar page. This page covers a broad parent topic comprehensively but without granular depth. The supporting pages—the individual keyword clusters you mapped out—handle the specific subtopics.
For our B2B software example, "workforce management" is the broad pillar. The supporting clusters cover specific applications: "overtime compliance tracking," "shift swapping policies," and "mobile punch-in systems." Each supporting page links back to the central pillar, passing authority upward and demonstrating that the site covers the entire ecosystem of the topic.
Mapping parent topics and subtopics
When mapping this out, the hierarchy needs to reflect how users actually research the space. If we group isolated terms without assigning them a structural role, the resulting site feels disjointed. Assign entire clusters to specific structural roles so every piece of content has a distinct purpose. This prevents the common trap of publishing disconnected articles that never aggregate into measurable authority.
Why keyword clustering matters for topical authority
Isolated content rarely performs well in a competitive landscape. Websites that implement a topic cluster architecture experience an average organic traffic increase of 43% compared to websites that don't use structured content grouping. The reason comes down to resource allocation and clear architectural signaling.
Preventing keyword cannibalization
When a content director notices organic traffic dropping for a core service, the common assumption is an algorithm update or a new aggressive competitor. Often, the root cause is self-inflicted: two different blog posts on the same site are competing against each other for the exact same intent.
Keyword clustering significantly mitigates content cannibalization by ensuring each page targets a unique set of semantically related keywords. If you already have a page ranking for "employee scheduling software," clustering ensures your team doesn't accidentally publish a new post targeting "staff rostering app." You optimize the existing asset instead of diluting your site's ranking power across multiple weak URLs.
Evaluating aggregate traffic potential
Individual keyword volume is notoriously misleading. A single term might show 200 monthly searches, which looks barely worth the effort. But when you group that term with fifty related semantic variations, the cluster's aggregate volume might exceed 4,000 monthly searches.
Aggregate metrics change how you prioritize content production. You stop chasing isolated high-volume terms that are impossible to rank for, and start building comprehensive pages that naturally capture hundreds of long-tail variations.
Building a verifiable framework
Connect your thematically grouped clusters to a pillar page to create a comprehensive framework. When search engines crawl a site with this architecture, they evaluate the entire interconnected cluster rather than judging a single page in a vacuum. This depth protects your rankings. It's much harder for a competitor to outrank a network of twenty expertly linked articles than it is to outrank a single standalone post.
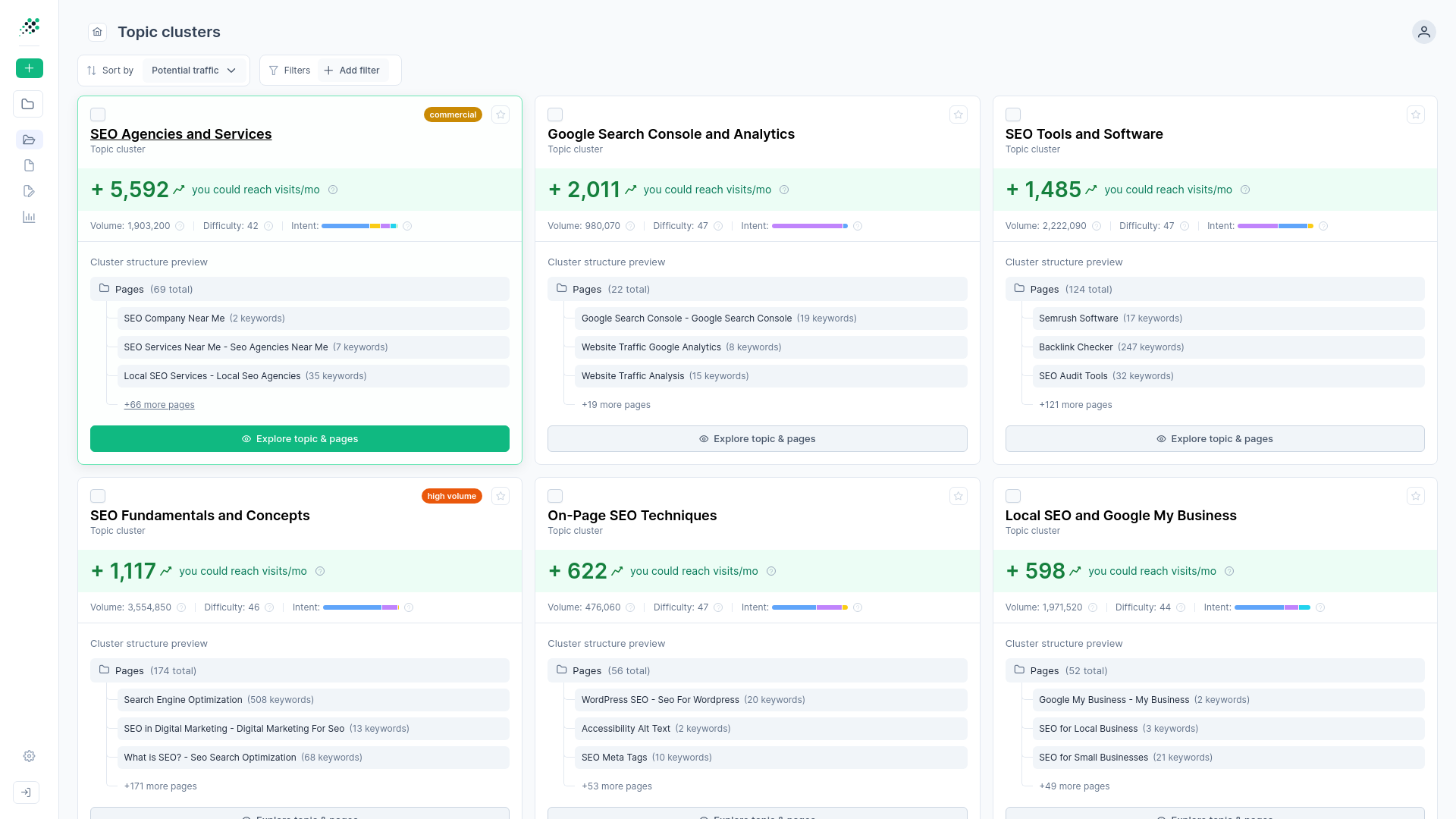
How to automate your keyword clustering workflow
-
Choose your initial research input mode
Start a new project and select Keyword, URL, or Domain mode to establish your seed input. RankDots gathers variations and search data, leaving you with a populated starting list.
-
Import and merge your historical data
You can upload historical exports from other tools directly into your active workspace. RankDots deduplicates and merges these terms so you have one clean database ready for analysis.
-
Run the automated semantic clustering pipeline
Once your list is ready, start the clustering process to organize your database based on live search results and dominant user intent. You'll see your flat text list transform into distinct parent topics and specific subtopics.
-
Sort clusters by aggregate traffic potential
Filter your newly formed groups using the built-in Traffic Growth algorithm to find immediate targets. The dashboard reorganizes your view so the highest-potential content opportunities sit at the very top.
-
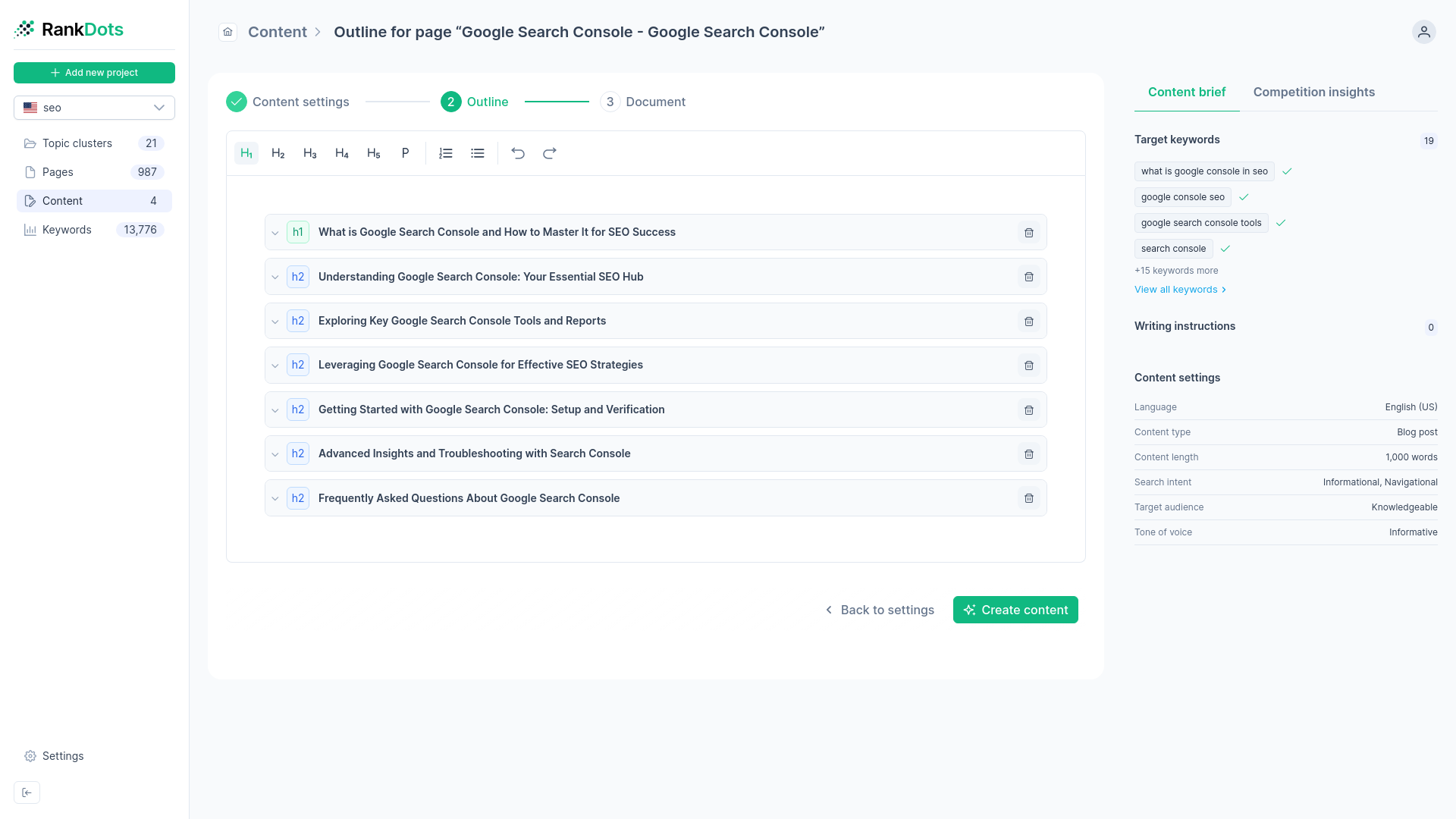
Send priority groups to the writer
When you find a high-value topic cluster, push it directly to the built-in content writer. Your new draft automatically includes the exact SERP analysis and intent data captured during the research phase.
Step 1: Gather your raw keyword data
You can't build a robust architecture on a thin dataset. SEO professionals typically spend an average of three to five hours per client during each research cycle manually sorting, filtering, and clustering keywords in spreadsheets. To make that time investment worthwhile, the initial data collection phase must be exhaustive.
Compiling terms from multiple sources
Pull raw keyword data from every reliable source available. Sticking to a single tool usually leaves blind spots. Export lists from your primary SEO research platform, pull historical query data from your site's search console, and scrape autocomplete suggestions directly from search engines.
If we're mapping the workforce management space, we want everything from broad head terms to the highly specific problems buyers are trying to solve. Consolidate these exports into a single centralized repository before attempting any sorting.
Capturing the long-tail variations
Nearly 96.55% of web pages receive little or no organic traffic from Google, often due to targeting isolated head keywords instead of using a topical strategy that captures the long tail.
Question-based queries and conversational phrases might show low individual search volume, but they often carry the highest conversion intent. Someone searching for "workforce management" is just browsing. Someone searching for "how to track employee overtime across multiple locations" is actively looking for a solution. Ensure your data pull includes these specific, multi-word variations.
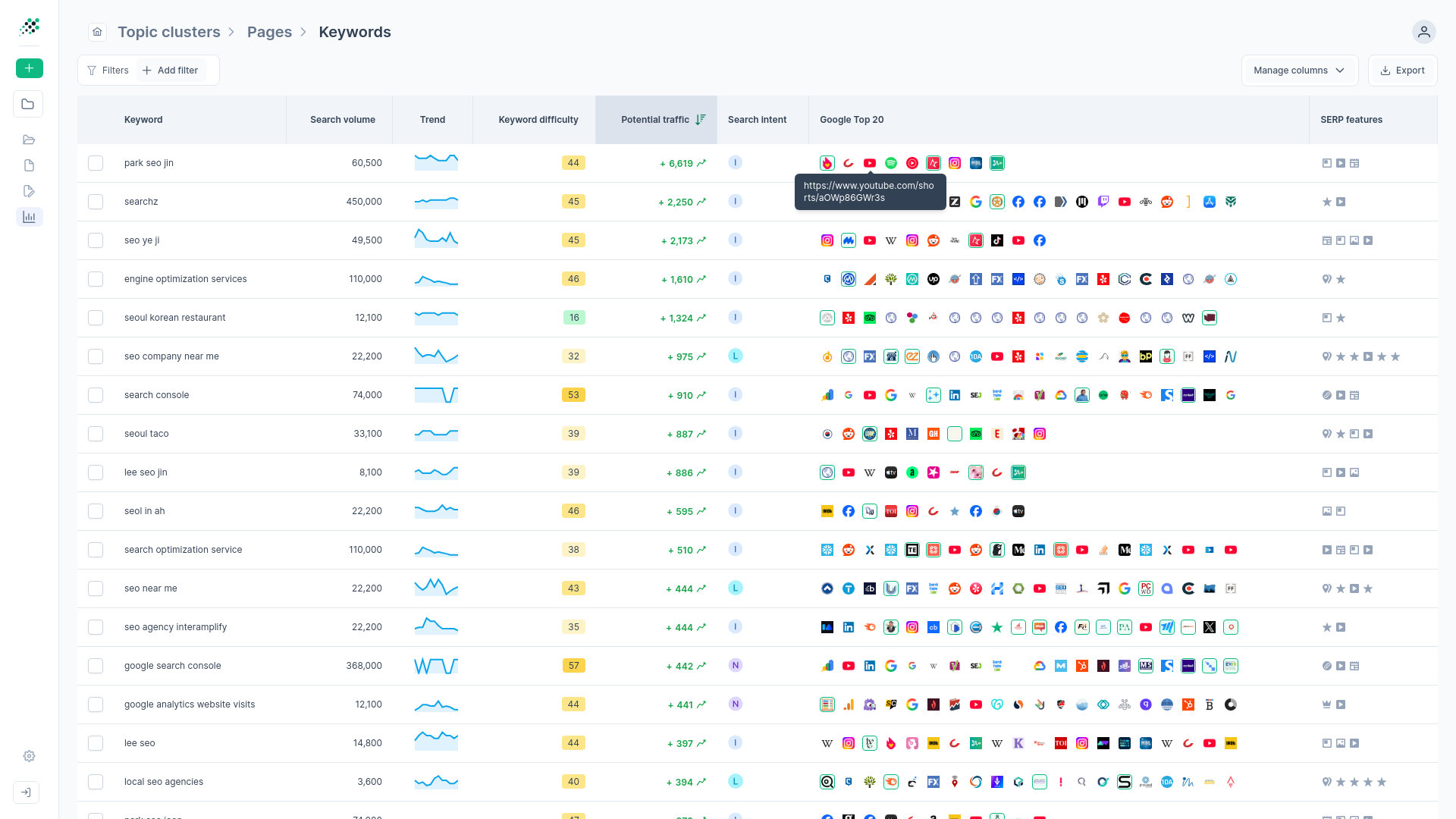
Collecting the necessary metrics
A raw list of words is useless without the context needed to prioritize them. During the export process, ensure you pull the associated search volume, keyword difficulty, and current ranking positions for every term.
These metrics act as the filtering mechanism later in the process. You'll eventually need to determine which clusters represent realistic opportunities and which ones are too competitive for your current domain strength. Accurate volume and difficulty data prevent those strategic decisions from turning into guesswork.
Step 2: Clean and filter your keyword list
Merge your exports from various platforms into one master spreadsheet before applying any filters. Deduplication is the required first step when combining data from multiple tools, as the same query will often appear with slightly different search metrics. Keep the row with the most robust data and delete the duplicates.
Clean the list carefully. Strip out irrelevant terms immediately. Filter out queries related to distinct geographical markets you don't serve, and remove branded terms belonging to your competitors. Unless you plan to build a dedicated comparison page, trying to rank for another company's brand name usually results in high bounce rates and wasted effort.
Set a baseline volume threshold that matches your domain's current authority. A brand new website should keep low-competition queries in the long tail even if they show zero or ten monthly searches. An established site with high authority might set a floor of fifty or one hundred searches to focus resources on larger opportunities. We generally lean toward keeping the threshold low during the initial clean-up, as those granular terms often become valuable supporting topics later in the process. Filter aggressively for relevance, but be conservative when filtering by volume.
Step 3: Analyze SERP intent for your target terms
Every query falls into an informational, navigational, commercial, or transactional bucket. Group your cleaned list by these broad categories first.
Proper search intent mapping at this stage ensures we don't accidentally merge terms that demand entirely different page structures. A user searching for "what is workforce management software" needs a high-level educational guide. Someone searching for "workforce management software pricing" expects a direct commercial breakdown. Mixing these intents on a single page confuses the reader and fails to satisfy the search engine's expectations. Intent dictates the format.
Verify assumptions against live results
Don't guess what a query means based solely on the words used. Manually review the top 10 search results for your most important target terms. You might assume a specific phrase implies research, but the live search results might reveal a wall of product landing pages. If the first page consists entirely of e-commerce category pages, a long-form educational blog post won't rank, regardless of how well it's written.
Match the expected content format
The ranking pages provide a blueprint for what the algorithm currently rewards. Look at the structures dominating the first page. Identify whether the winners are listicles, comprehensive how-to guides, interactive tools, or short FAQ pages. If eight of the top ten results are product comparison tables, your content must include a comparison table to compete. The goal is to align your cluster's output with the exact structural format the user expects to find.
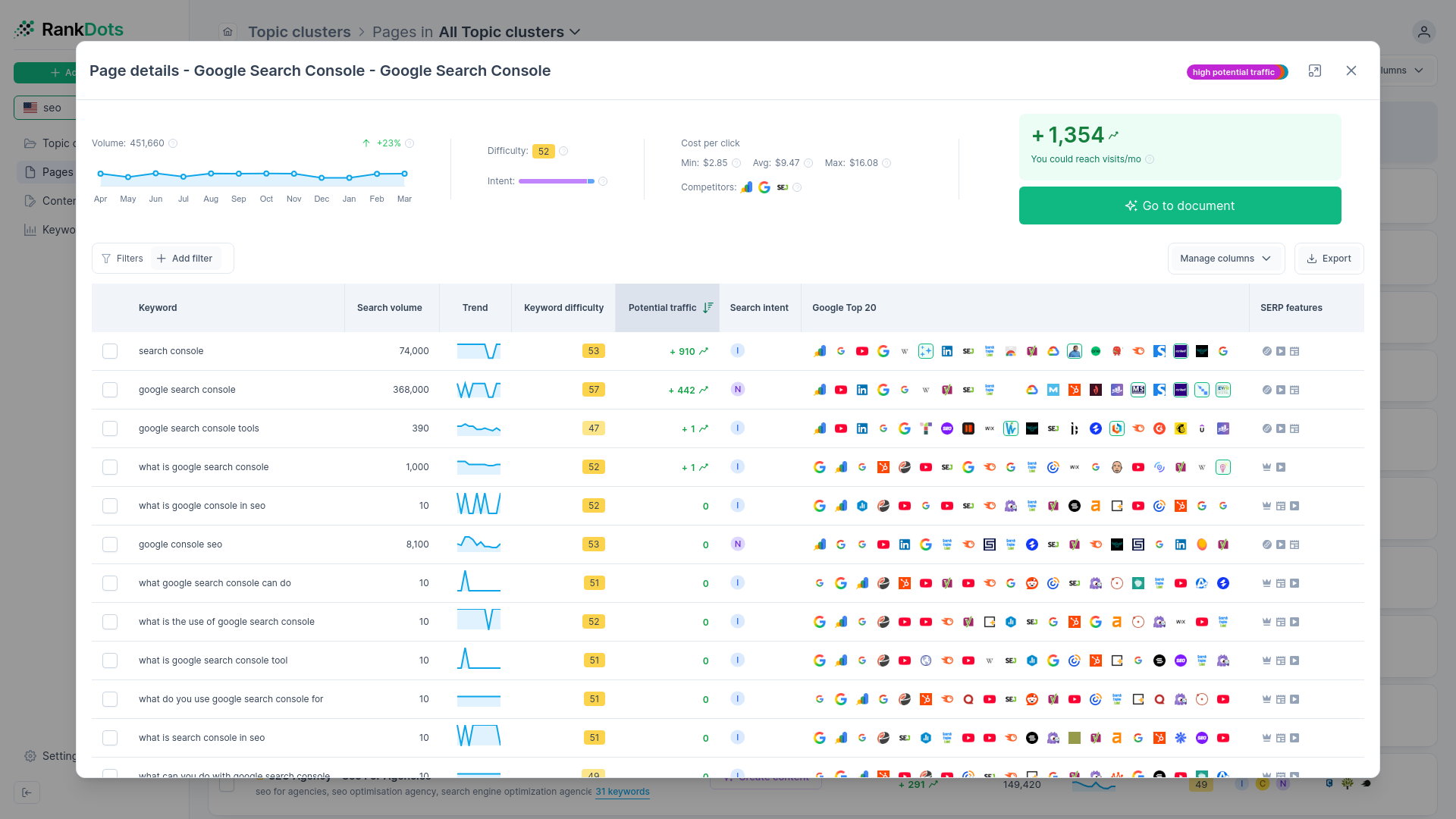
Step 4: Group keywords by SERP overlap
Basic n-gram tools group keywords by looking for shared words. If two queries share a core phrase, the tool lumps them together. We've noticed this pattern cause significant architectural problems because it ignores actual search behavior. Two phrases can share identical words but demand completely different pages, while two phrases with zero shared vocabulary might satisfy the exact same user need.
Validate shared intent with URL intersection
The only reliable way to know if two keywords belong in the same cluster is to check if they share the same ranking pages. This mechanism is called URL intersection. If Google ranks the same three URLs on the first page for both "employee shift planner" and "staff scheduling app," the algorithm considers those queries semantically identical. They share the same intent and belong in the same cluster. If the ranking URLs are completely different, the terms require separate pages.
As a general guideline, finding three to four overlapping URLs in the top ten results provides enough evidence to justify grouping the terms together.
Set strict overlap thresholds
It's genuinely tricky to decide how many identical URLs justify a cluster. Suppose you're trying to determine if a subtopic like "shift swapping policies" should be its own dedicated page or simply folded into a broader workforce management guide. Basic tools can't answer this. You need data-driven confidence before committing production budget.
Automated validation solves this. With the URL Intersection Validation algorithm in RankDots, you can handle this quality check automatically. After initially clustering the data, the system checks if the exact same URLs rank in the search engine for multiple keywords within that proposed group. If the overlap is strong, it validates the cluster. If the URLs diverge, it signals that the proposed group is too broad and automatically separates the terms into distinct topics. This prevents costly mistakes.
Step 5: Map your clusters to a topic-first site architecture
Your grouped keywords must now translate into actual pages. Map your broadest, highest-volume clusters to act as parent pillar pages. These are the central hubs of your topical authority. Make the narrower, highly specific clusters your supporting subtopic pages. This is the actual architecture. Every supporting subtopic page must link directly back to its designated parent pillar, passing authority upward and creating a clear semantic relationship.
Prioritize the production queue
Single-keyword volume is a terrible metric for prioritizing content. Evaluate the aggregate opportunity. Imagine a content marketer needing to present a prioritized editorial calendar to stakeholders. A pitch for a single keyword with 150 monthly searches rarely secures budget approval. However, pitching an entire topic cluster that aggregates 40 related terms for a combined traffic potential of 3,500 monthly searches completely changes the conversation. Cluster-level traffic potential and aggregate keyword difficulty provide the concrete metrics needed to justify your strategy and tackle the most profitable topics first.
Automate the hierarchy mapping
Manual mapping of hundreds of keyword groups takes days and often results in overlapping pages. Modern workflows bypass this manual sorting entirely.
The Topic-First Architecture capability in RankDots reverses the traditional workflow. Instead of starting with a massive list of keywords and trying to forcefully map them to existing pages, the platform builds topic clusters first and derives the optimal page structure directly from that data. Each clustered group automatically maps to a recommended page type, and keywords are assigned based strictly on their shared search intent. This approach directly outputs a finished site architecture, preventing the structural keyword cannibalization common in manually built sites.
Choosing between manual and automated clustering tools
Manual sorting doesn't scale. Hand-sorting rows burns unbillable hours and invites human error, especially when you try to spot URL intersection patterns across thousands of rows by eye.
An automated clustering pipeline eliminates this bottleneck. When evaluating an automated tool, look past the marketing claims and test three specific criteria. First, check the data processing limits to ensure the platform can handle your total keyword volume without crashing. Second, verify whether the tool uses live search engine results for intersection mapping or relies on outdated natural language processing algorithms. Finally, evaluate the cost structure, as many platforms charge per clustered keyword, which quickly becomes prohibitive for large sites. Here's how the top platforms on the market compare against these requirements.
Keyword Insights
If you manage massive datasets across multiple international markets, Keyword Insights handles the heavy lifting. Keyword Insights processes up to 200,000 keywords per upload using live country-specific SERP data, with total clustering limits reaching 2.5 million keywords.
The standout feature is how it bridges the gap between research and production. Instead of exporting data to another platform, you can generate AI content briefs and outlines directly from your clustered keywords. Internal brief generation keeps the initial search intent context firmly attached to the writing assignment.
The tradeoff involves the pricing model. The platform operates on a strict credit-based usage system, with the Basic plan reportedly starting at $58 per month based on a monthly allowance. Since the platform lacks comprehensive technical SEO and backlink analytics, you'll still need an additional suite for broader site health monitoring. We usually recommend it as a specialized add-on for high-volume content operations rather than a standalone replacement.
Ahrefs
Ahrefs takes a highly streamlined approach to grouping. The platform automatically clusters keywords by their Parent Topic using real SERP overlap data.
The methodology immediately surfaces specific cluster metrics, such as aggregate Traffic Potential and overall Keyword Difficulty. You see the true structural value of the topic at a glance. However, the system is rigidly defined. The clustering strictness is entirely automated and not user-configurable, meaning you can't adjust how closely terms must match to form a group. The tool also doesn't natively map semantic entity relationships.
Pricing reportedly starts at $29 per month for a limited Starter plan, but gaining access to the standard feature tiers requires $129 per month. If your team already uses the software as a primary research suite, the built-in grouping offers a fast, low-friction way to view consolidated data without paying for a separate specialized clustering application.
Frequently asked questions
How many keywords should be in a single cluster?
What tools are available for keyword clustering, and are there free options?
What is a real-world example of a keyword cluster?
How long does it take to see results from topic clustering?
Next steps for your content strategy
Research is just the start.
We often see content teams eager to write, but moving the clustered data from spreadsheets into actual writing prompts is disjointed and slow. When you export clusters to external writing tools, you often lose the specific SERP analysis and intent data that defined the group in the first place. You need an automated pipeline that translates research directly into content briefs.
Once you set your workflow, prioritize execution. Start with the lowest-competition clusters first. Focus on topics related to a single product or service line so you can build your authority across other platforms that search engines and AI systems draw from.
Track your progress carefully. Topic clusters give you an easy way to see which silos of your website perform well and which decline. Align that ranking data with what matters most to your business, and focus your production schedule on the exact pillars driving immediate revenue.
Turn raw keyword data into a structured traffic engine
Stop wasting unbillable hours sorting spreadsheets. Our automated keyword clustering pipeline maps your topics directly to a finished site structure to capture aggregate search volume without manual guesswork.