Stop using flat lists: Scale topical authority with keyword clustering using AI tools

Your SEO strategy might be working against itself if you still rely on flat keyword lists, risking split authority every time you publish a new page for a single term variation. Keyword clustering using AI tools automates the grouping of search terms based on semantic intent and live SERP overlap, rather than just shared words. The clustering process helps you quickly build pillar-and-cluster site architectures, eliminate keyword cannibalization, and accurately map content strategies to secure topical authority.
We consider SERP-based grouping the only reliable way to mathematically prove which keywords belong together before you assign a single brief.
When auditing massive flat lists, we often see teams try to untangle messy, legacy architectures manually. They spent days exporting massive lists from basic planners and manually sorting them in spreadsheets. The result wasn't a cohesive strategy—three different articles ended up competing for the exact same search query variations because they were built from isolated lists instead of structured groups.
Here is a complete strategic framework for evaluating AI grouping methodologies and deploying a SERP-validated content architecture.
Quick Takeaways
- Keyword clustering using AI tools actively groups search terms based on live search engine result overlap and true semantic intent, instantly transforming flat spreadsheets into authoritative pillar-and-cluster site architectures.
- Moving beyond basic lexical matching allows you to group highly relevant terms that share zero root words, capturing exactly how users search rather than just the syntax they type.
- Discover why relying solely on natural language processing models often fails, and how URL intersection validation acts as a mandatory reality check to ensure search engines will actually rank your targeted terms together.
- Protect your strategy from the hidden search volume overestimations found in standard planner exports by systematically normalizing your raw data before any grouping begins.
- Learn how to precisely manipulate SERP overlap thresholds to customize cluster sizes, helping you strategically uncover low-competition subtopics that deliver quick traffic wins.
- Instantly diagnose legacy site architecture failures by cross-referencing your current live pages against AI-generated clusters to eliminate hidden keyword cannibalization and consolidate split link equity.
AI clustering mechanics: Flat lists versus pillar-and-cluster architectures
Most traditional keyword research leaves you with a massive, flat spreadsheet of terms sorted by volume. It tells you what people type, but gives zero architectural guidance on how to structure your website. A scalable content program requires moving away from one-dimensional data dumps and adopting a topic-first mindset.
Morphological versus semantic intent grouping
We've noticed a major flaw in how legacy systems handle keyword grouping. They rely heavily on morphological matching—putting terms together simply because they share the exact same root words (like "running shoes" and "shoes for running"). But true search intent matching requires looking at the meaning behind the query.
For an auto insurance site, "affordable auto insurance" and "cheap car coverage" need to belong in the same cluster. They share zero words, but the underlying intent is identical. Solve this by understanding what searchers actually want. Lexical matching just gets in the way of real intent. When you rely on semantic meaning, you capture how users actually search for solutions. Shared syntax misses the entire picture.
Building the architectural blueprint
Flat keyword buckets make it impossible to scale a site logically. The alternative is mapping your content into a defined hierarchy before you brief a single writer. Randomly assigning terms to standalone pages scatters your authority. Organize them into a strict two-level structure.
You can use RankDots to organize keywords strictly into Parent topics and Subtopics. This structure maps directly to pillar-and-cluster site architectures.
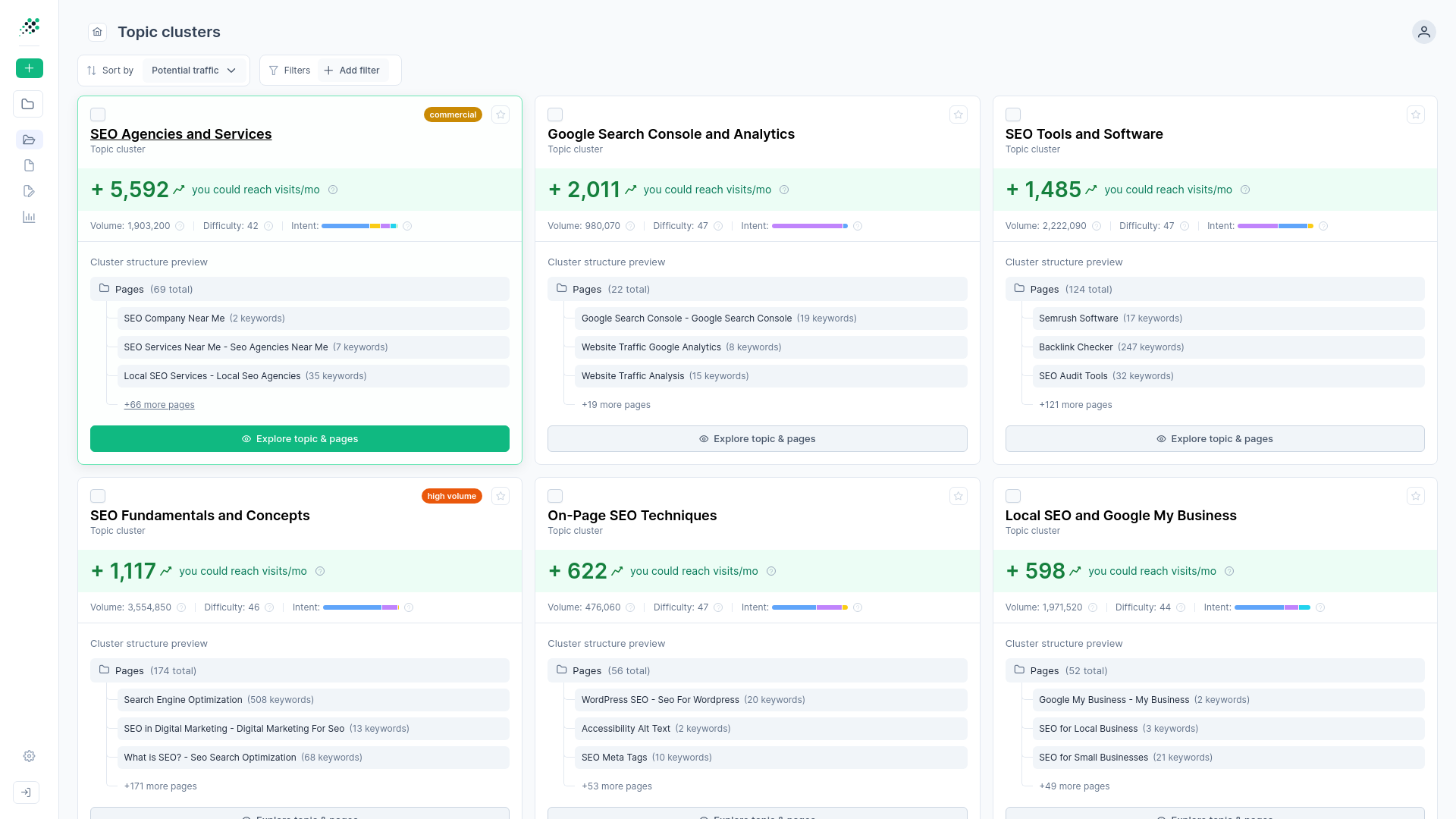
A hierarchical structure forces you to define parent and child relationships immediately. You skip the ambiguity of manual spreadsheet sorting. The broad thematic area dictates your primary pillar page, while the specific angles naturally form your supporting blog posts. Defining these exact boundaries prevents keyword cannibalization. It ensures every planned page has a distinct place within the broader topic ecosystem.
Categorizing by search intent
What does someone typing "best crm for small restaurants" actually want—a directory, a review post, or a signup page? Probably not the same thing the person typing "what is a crm" expects to see.
When AI detects search intent categories within a grouped cluster, it categorizes keywords by their dominant behavior, such as informational versus transactional. You can make much better decisions about which clusters require direct-response landing pages and which need deep-dive educational guides. If you miss that crucial distinction, pages might manage to rank but they will entirely fail to convert. The gap between ranking and converting is almost always an intent-mapping failure, not a content quality issue.
Methodology comparisons: Semantic similarity versus URL intersection validation
Semantic grouping is an upgrade over basic word matching, but it still has a blind spot. Pure natural language processing models assume the search engine completely agrees with the AI's logic.
The limits of pure semantic NLP
Language models are incredibly effective at understanding that two phrases mean the same thing in a vacuum. But live search environments are messy and unpredictable. Sometimes, a search engine decides that two highly similar phrases actually require completely different page formats.
If you group terms blindly based on semantic closeness, you might build a single comprehensive pillar page targeting intents that the search engine absolutely refuses to rank together. You could spend weeks writing a definitive guide only to discover that Google expects a short-form product category page for half of the terms you included.
Mechanics of URL intersection validation
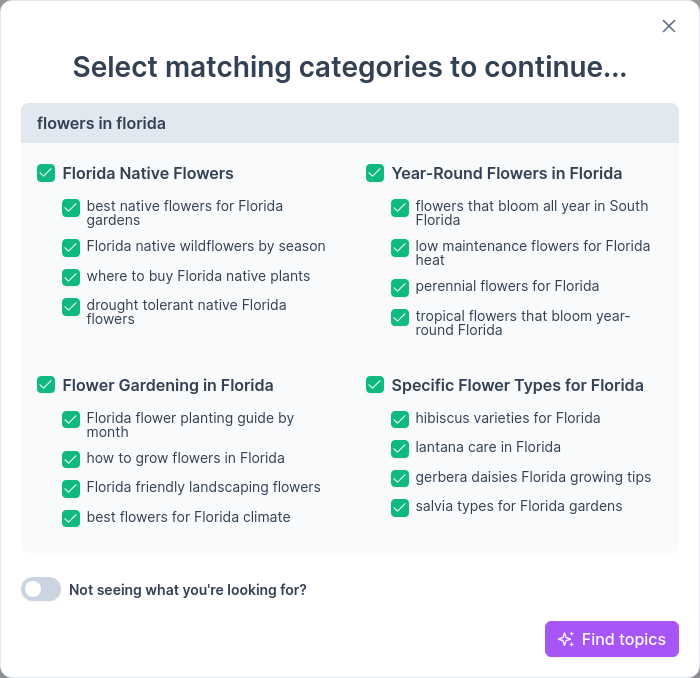
Validation against live search engine results pages becomes mandatory here. URL intersection validation is a definitive reality check for your content architecture. After an initial grouping, the system actively checks the live SERPs to see if the same URLs rank for multiple keywords within that proposed cluster.
If the same URLs consistently show up for both queries, you have undeniable proof that the search engine views these keywords as related. If they don't, the cluster is probably too broad and needs splitting. Validate URL intersections in RankDots. This aligns your clusters strictly with actual ranking behavior. You're letting the search engine do the heavy lifting of proving what belongs together.
Proving intent without shared words
We consistently see distinct terms that share zero words but return identical ranking pages. In the auto insurance niche, "minimize premium costs" and "cheap policy" look completely unrelated to a basic lexical filter.
But when you apply SERP reverse-engineering, you often find the same top ten ranking pages for both queries. That intersection proves they belong on the same page. URL validation stops you from splitting those terms into two separate, competing articles. Validating against actual SERP overlap is the only reliable way to ensure your content matches reality.
AI Clustering Tools Capability Comparison
| Platform | Methodology | Key Capability | Starting Price |
|---|---|---|---|
| RankDots | SERP URL intersection validation | Distributes aggregated search volume accurately | Contact for pricing |
| Keyword Insights | Live SERP data analysis | Processes up to 200,000 keywords | Starts at $58/month |
| Keyword Cupid | Neural network grouping | Generates interactive visual mind maps | Subscriptions with $1 trial |
| Keyword-Cluster | Generative AI visibility tracking | Detects 50 specific search intents | Starts around €70/month |
| Answer Socrates | Basic semantic clustering | 1,500 free monthly clustered keywords | Starts at $9/month |
Why default exports from Ahrefs and Semrush fall short
Most SEO workflows start with a broad export from a major industry planner. Platforms like Ahrefs and Semrush provide massive databases for initial discovery, but building your architecture strictly from their default CSV exports causes problems later.
Search volume overestimations
The biggest hidden risk in standard planners is how they handle aggregated metric groupings. Traditional tools frequently bundle similar keywords together and then report the total group volume for every keyword in the set.
If a planner decides "running shoes" and "shoes for running" belong in the same group, it applies the combined search total to both rows in your spreadsheet. Aggregating these numbers inflates search volume estimates. You end up building financial models and forecasting traffic demand that simply doesn't exist in reality. When you base a year-long content sprint on inflated numbers, the eventual ROI will always look like a failure to your stakeholders.
The time cost of manual manipulation
A 50,000-term export from a legacy planner leaves you with nothing but a raw data dump. Manually manipulating that spreadsheet for a large enterprise website requires hours of tedious work.
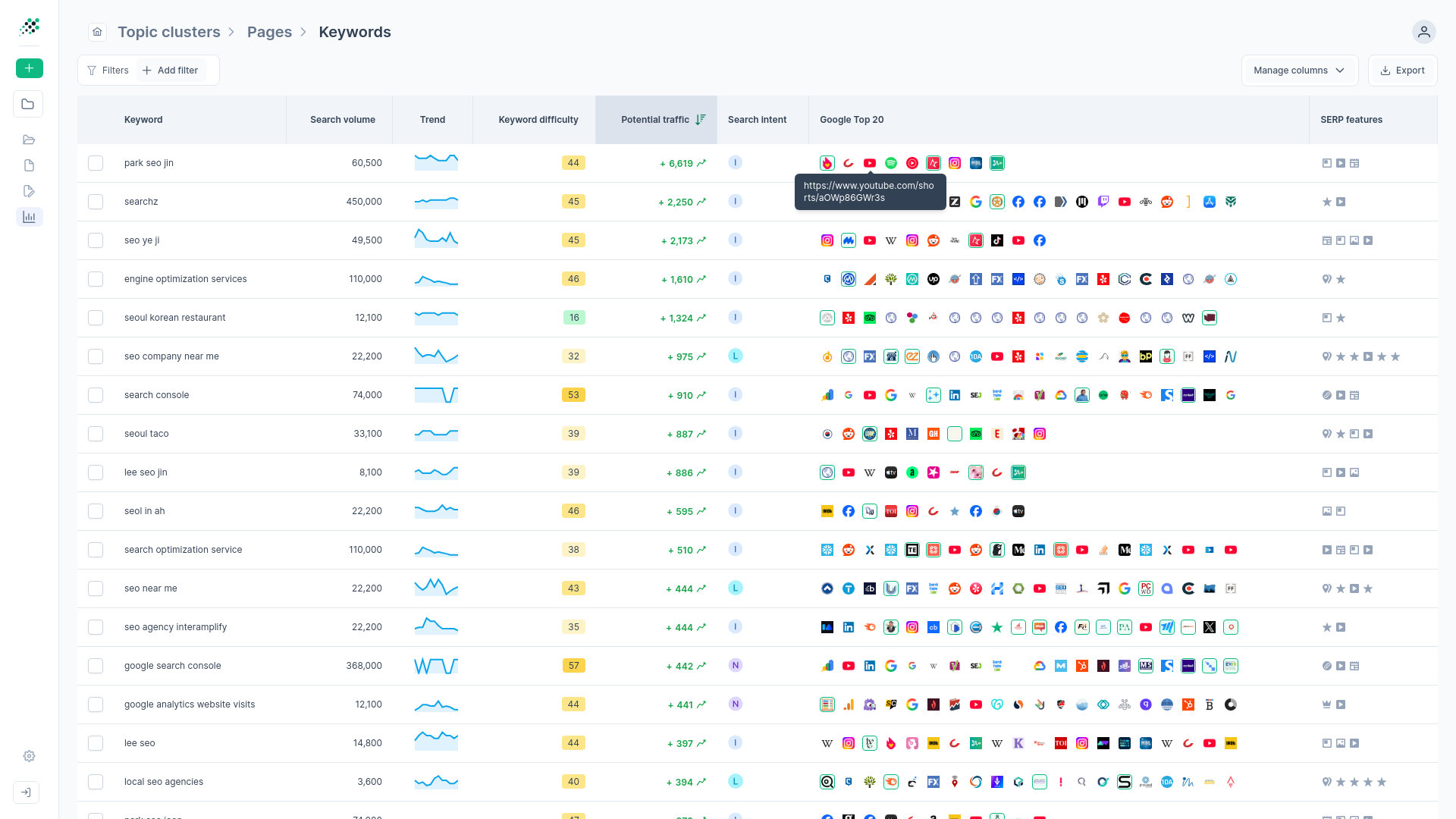
You'll spend days of focused work sorting, deduplicating, and attempting to manually eyeball semantic relationships across thousands of rows. Untangling a legacy site's keyword map manually takes hours of tedious work and leads to costly mistakes. It's a terrible use of a strategist's time to do what an algorithm can finish in seconds.
Isolated keyword difficulty scores
Standalone keyword difficulty scores present another trap for content teams. A single query's difficulty score ignores the critical cluster-level context when viewed in isolation.
A specific term might show a high difficulty score. But if it belongs to a parent topic where your domain already has established authority, your actual barrier to entry is much lower. Default flat-list exports can't provide this architectural context. You end up making strategic decisions based on incomplete data.
Step-by-step implementation workflows for SERP-validated clustering
Moving from manual spreadsheet sorting to automated AI clustering requires a clear, defined workflow. We recommend standardizing exactly how your team imports, processes, and refines data before any writing begins.
Data import and normalization
Your first step is gathering raw keyword data from multiple disparate sources. You might pull historical queries from Google Search Console, generate new ideas through AI tools, and export baseline data from legacy planners. When you combine these lists, you inevitably create duplicates and conflicting metric sets.
A proper workflow automatically normalizes this data upon entry. If a keyword is found across multiple sources, the system must keep the best available metrics—highest verified volume, most complete SERP data, and lowest difficulty—to create one clean, unified list. Some teams rely on Keyword Insights, which supports processing up to 200,000 keywords at a time, to handle this scale. Others use tools like Keyword Cupid to visualize these massive lists into interactive mind maps. Regardless of the tool, normalization prevents you from clustering garbage data.
Adjusting SERP overlap thresholds
Once the data is normalized, the clustering engine takes over. But you should never treat AI grouping as a rigid black box. You need the flexibility to adjust the grouping sensitivity, commonly referred to as the SERP overlap threshold.
We usually start by defining the threshold based on the site's competitive strength:
- High threshold (e.g., 7+ matching URLs): Creates very tight, specific clusters. Best for highly competitive niches where you need dedicated, hyper-focused pages to stand out.
- Medium threshold (e.g., 4-6 matching URLs): The standard setting we use for most typical pillar-and-cluster architectures.
- Low threshold (e.g., 2-3 matching URLs): Creates broad, expansive clusters. Highly useful for identifying high-level parent topics during your initial research phase.
These threshold adjustments directly influence the tightness or broadness of your clusters. Adjusting these settings adapts the site architecture to your domain strength. Never rely on a universal default.
Identifying low-competition subtopics
With a fully clustered keyword map in hand, you still have to decide exactly what to write first. Hundreds of organized clusters won't automatically tell your team which specific topics offer the best effort-to-reward ratio.
You need workflows that actively highlight low-competition subtopics buried inside broad parent clusters. Target the long-tail subtopics first. The primary parent pillar page often requires substantial link equity and months of waiting.
For a typical auto insurance site, this means ignoring "best auto insurance" on day one. Instead, build out specific subtopics like "auto insurance requirements for leased vehicles" and "how speeding tickets affect premium renewals." Long-tail subtopics build foundational relevance for the parent topic over time. It delivers quick traffic wins for stakeholders. It also supports your broader topical authority campaigns from the ground up.
Content strategy integration: Mapping clusters to topical authority campaigns
A routine site audit often reveals the true cost of legacy keyword research. One common symptom is structural failure. Three separate articles competed for the same query variations. One page covered "average car insurance costs," a second tackled "typical auto premium rates," and a third focused on "what to expect for car insurance pricing."
Because the previous team built their content calendar from flat, alphabetized spreadsheets, they completely missed the overlap. They split their ranking power three ways. A cross-reference audit identifies active keyword cannibalization before you waste resources updating the wrong pages.
The mechanics of this cross-referencing audit are straightforward. You export your current site index and run those URLs against your newly generated AI clusters. A health check quickly flags anomalies. If one URL spans multiple distinct clusters, your page is likely too broad and lacks specific focus. If you find five live URLs mapped to a single tight cluster, you're cannibalizing your own traffic.
You resolve the collision by choosing the strongest page as the primary target. You merge the redundant posts into one definitive pillar asset and redirect the old URLs. The resulting single page consolidates link equity and immediately performs better than the three fragmented pieces ever did.
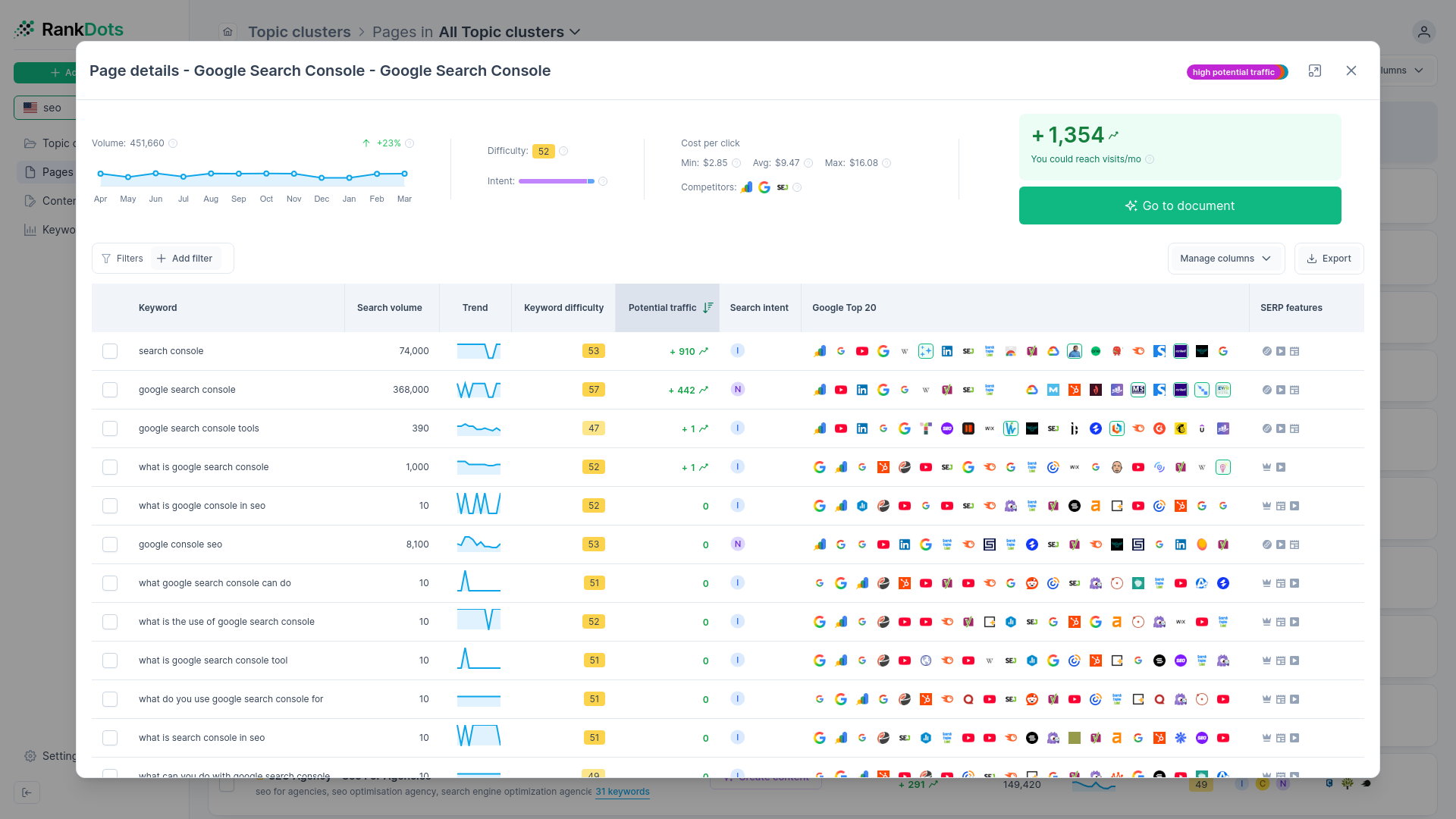
Utilizing intent categorization for format selection
Correctly grouped terms handle the site architecture, but you still have to decide what the page actually looks like. The most common mistake we observe in content production is a total mismatch between the keyword's underlying intent and the final page format. Writers often deliver 3,000-word educational guides for queries where the user just wants a simple pricing calculator or a direct product comparison.
Intent categorization dictates the format of landing pages versus informational blog posts with zero guesswork. If the cluster validation shows that searchers want a transactional experience, you build a direct-response landing page. If the intent is purely educational, you assign a long-form guide.
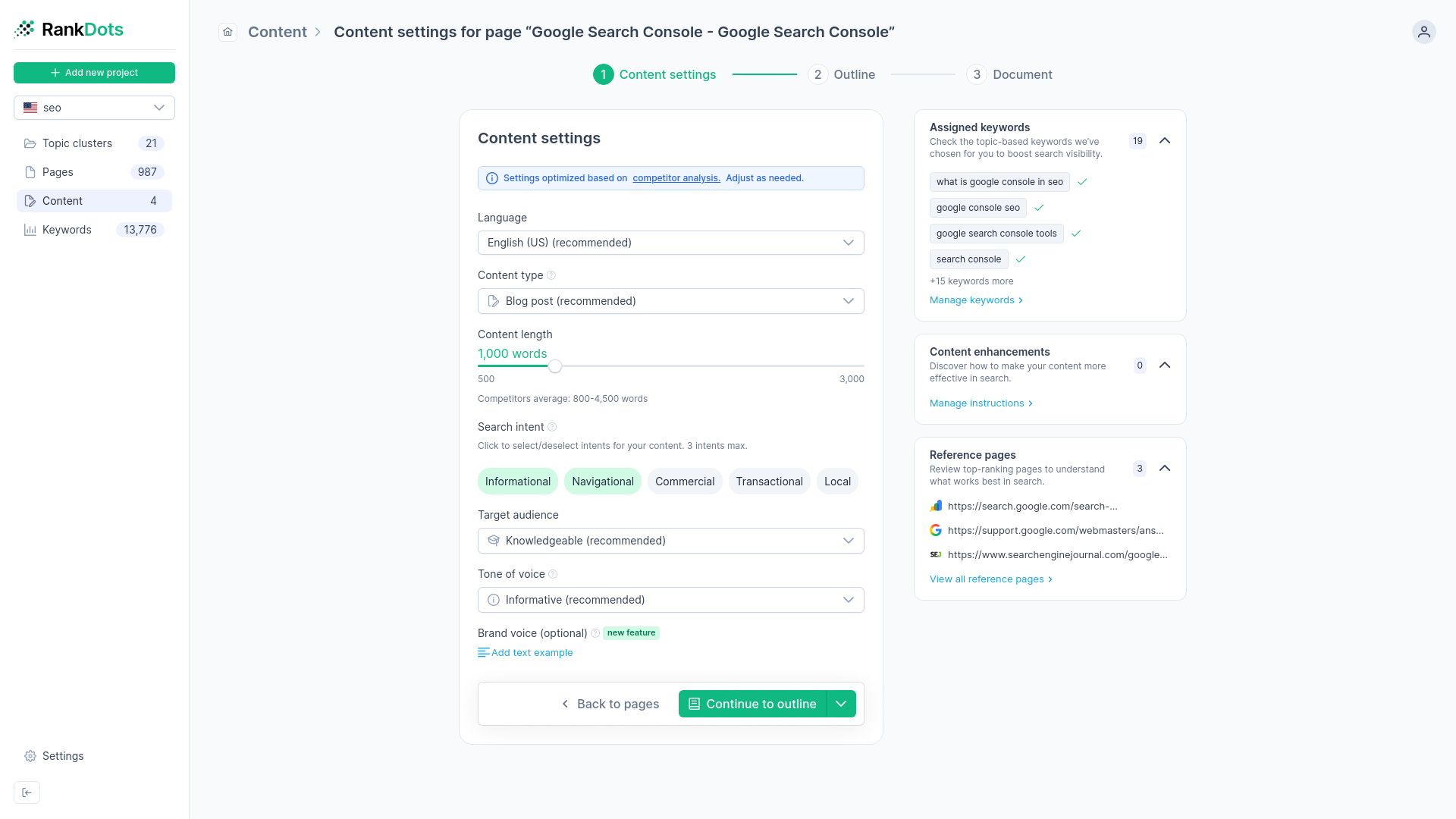
You can use intent detection features to automatically identify specific content formatting requirements and over 50 search intents directly from the live results. Establish the precise page format during the outline phase. Don't guess what the search engine prefers. When you match the structural format to the searcher's true goal, conversion rates improve. Traffic only matters if the page design facilitates the action the user expects to take.
This approach also saves your team significant time. The clustering engine handles the SERP analysis so you don't have to review individual search results manually for every brief. Teams using automated intent categorization significantly reduce their brief creation time. You know exactly what components belong on the page before the writer types a single word. Some SEO platforms evaluate over 500 factors to recommend actionable content improvements based on those specific formats.
Translating clusters into production sprints
A massive architectural map looks great in a spreadsheet, but it doesn't execute itself. You have to translate those topic clusters into distinct, monthly production sprints. A map of 5,000 keywords is overwhelming until you slice it into distinct, actionable monthly phases.
We typically structure sprints around a single parent topic at a time. Month one focuses entirely on deploying the primary pillar page and the first tight batch of supporting subtopics. You establish the core thematic footprint. Month two expands into adjacent subtopics to build out the cluster's long-tail relevance.
Prioritization requires data, not intuition. We use the five recommendation algorithms in RankDots to score and prioritize keywords within your clusters. You pinpoint the subtopics with the lowest barrier to entry and target those exact pages in your first sprint. Early traction on low-competition subtopics builds the domain momentum required to eventually rank the highly competitive parent pillar.
The handoff to the writing team also benefits from automation. Some workflows automatically produce AI-optimized content briefs straight from the approved clusters. You skip the tedious manual outlining phase entirely. Interactive mind maps help visualize the parent-and-child relationships. Writers see exactly how their assigned piece connects to the broader site architecture.
When you batch related subtopics, internal linking gets much easier. Because you publish a batch of related subtopics simultaneously, you map out the exact anchor text and interlinking paths before the pages go live. Every subtopic links back up to the parent pillar, and lateral links connect related supporting pieces. When you integrate keyword clustering using AI tools directly into your production calendar, you stop publishing random articles and start constructing a cohesive, mathematically validated content ecosystem.
Frequently asked questions
What is AI-driven keyword clustering and how does it work?
Can AI-generated clusters cause keyword cannibalization?
How many keywords should be included in a single cluster?
What is the difference between a keyword cluster and a topic cluster?
Conclusion: Future-proofing your semantic SEO strategy
When evaluating platforms to transition an agency away from outdated lexical grouping methods, skepticism serves you well. Most generic systems group terms superficially. They look at basic text similarities instead of real ranking behavior. We look for tools that enforce strict URL intersection validation to prove true search intent before committing budget.
Moving from manual sorting to automated SERP validation completely changes how you build sites. It forces you to prioritize topic-first architectures over isolated keyword targeting. Search algorithms consistently refine how they understand complex natural language and semantic relationships. Sites built on tightly validated clusters naturally survive these algorithm updates because their architecture matches the engine's underlying structural logic.
Stop building isolated pages from flat spreadsheets. Adopt a SERP-validated clustering workflow to build authoritative ecosystems that search engines trust and users actually want to navigate.
Stop splitting your ranking power across competing pages.
You don't need to spend days untangling legacy spreadsheets. Keyword clustering using AI tools ensures every asset you publish targets a distinct, algorithm-validated intent boundary. Stop cannibalizing your own traffic and start mapping a profitable site structure today.